Contents
- xlrd/xlwt - 파이썬으로 엑셀 다루기
- xlrd/xlwt 설치하기
- xlrd 기본 사용
- xlwt 기본 사용
- xlrd/xlwt 조건식 사용하기
- xlrd/xlwt 여러 시트 다루기
- xlrd/xlwt 여러 파일 다루기
- xlrd/xlwt 통계 데이터 추출하기
- xlrd/xlwt 스타일 지정하기
- xlrd/xlwt 셀 병합하기
- xlrd/xlwt 열 너비 조절하기
Tutorials
- Python Tutorial
- NumPy Tutorial
- Matplotlib Tutorial
- PyQt5 Tutorial
- BeautifulSoup Tutorial
- xlrd/xlwt Tutorial
- Pillow Tutorial
- Googletrans Tutorial
- PyWin32 Tutorial
- PyAutoGUI Tutorial
- Pyperclip Tutorial
- TensorFlow Tutorial
- Tips and Examples
xlrd/xlwt 통계 데이터 추출하기¶
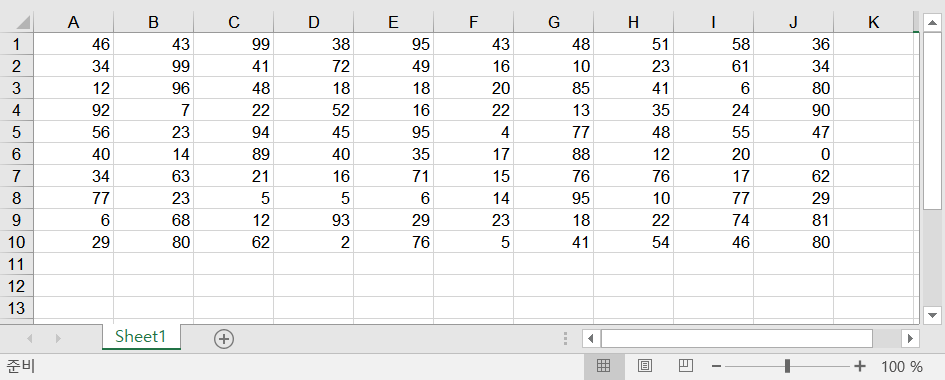
result.xls¶
xlrd, xlwt와 NumPy의 기능을 함께 이용해서 시트의 각 열에 있는 데이터의 통계적 데이터를 얻어 보겠습니다.
NumPy의 다양한 통계 관련 함수를 활용해서 각 열마다 합, 평균, 표준편차, 분산 데이터를 얻고,
각 열의 아래에 순서대로 작성해 보겠습니다.
예제¶
import xlrd, xlwt
import numpy as np
# 새로운 워크북, 시트 생성
wbwt = xlwt.Workbook(encoding='utf-8')
ws = wbwt.add_sheet('Sheet1')
# 엑셀 파일 읽기
wb = xlrd.open_workbook('result.xls')
sheets = wb.sheets()
# 행, 열 개수 가져오기
nrows = sheets[0].nrows
ncols = sheets[0].ncols
# 볼드 스타일 폰트 설정
font = xlwt.Font()
font.bold = True
style = xlwt.XFStyle()
style.font = font
# 각 열의 값에 대해 합, 평균, 표준편차, 분산 얻기
for i in range(ncols):
for j in range(nrows):
ws.write(j, i, sheets[0].cell_value(j, i))
col_values = sheets[0].col_values(i)
col_values = np.array(col_values)
# 통계 값 쓰기
ws.write(nrows, i, np.sum(col_values), style)
ws.write(nrows + 1, i, np.mean(col_values), style)
ws.write(nrows + 2, i, np.std(col_values), style)
ws.write(nrows + 3, i, np.var(col_values), style)
# 파일 저장하기
wbwt.save('result_stat.xls')
우선 새로운 시트를 만들어서 각 셀의 데이터를 옮겨서 써준 다음,
np.sum(), np.mean(), np.std(), np.var() 함수를 이용해서 각 열의 통계적 데이터를 얻습니다.
write() 함수의 네번째 파라미터에 적용할 스타일을 입력할 수 있습니다.
각 열의 아래에 순서대로 작성해주고 새로운 파일 (‘result_stat.xls’)로 저장합니다.
결과는 아래와 같습니다.
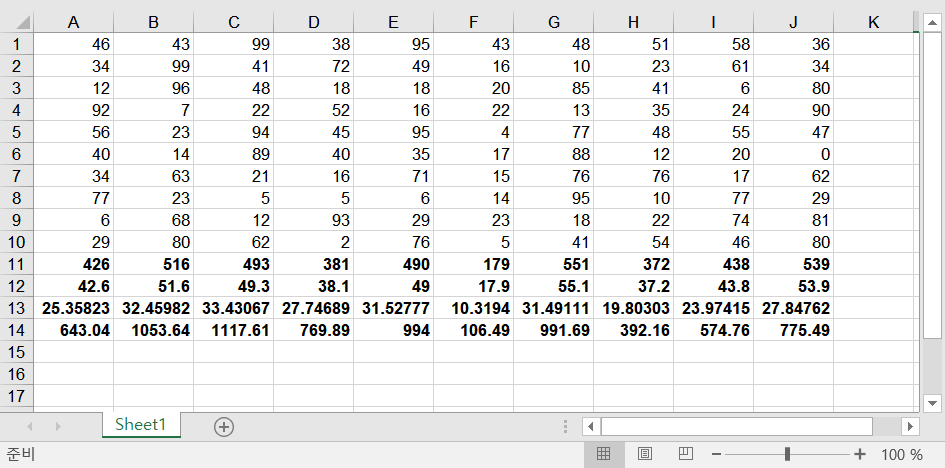
result_stat.xls¶
이전글/다음글
이전글 : xlrd/xlwt 여러 파일 다루기
다음글 : xlrd/xlwt 스타일 지정하기