Contents
- 강화학습 시작하기 (CartPole 게임)
- 환경 (Environments)
- 관찰 (Observations)
- 공간 (Spaces)
- 첫번째 알고리즘
- 첫번째 뉴럴 네트워크
- 강화학습 (Reinforcement Learning)
- Q-learning
- Deep Q-learning
- Epsilon-greedy 정책
- 첫번째 훈련
- Epsilon의 영향
Tutorials
- Python Tutorial
- NumPy Tutorial
- Matplotlib Tutorial
- PyQt5 Tutorial
- BeautifulSoup Tutorial
- xlrd/xlwt Tutorial
- Pillow Tutorial
- Googletrans Tutorial
- PyWin32 Tutorial
- PyAutoGUI Tutorial
- Pyperclip Tutorial
- TensorFlow Tutorial
- Tips and Examples
Deep Q-learning¶
Deep Q-learning은 학습 과정에서 Q-learning의 업데이트 룰을 적용합니다.
다시 말해서, 현태 상태 s를 입력으로 받는 뉴럴 네트워크를 구성하고, 뉴럴 네트워크가 상태 s의 모든 행동 a에 대해 적절한 Q(s, a) 값을 출력하도록 훈련시킵니다. 훈련이 이루어지고 나면, 에이전트가 가장 큰 Q(s, a) 값 을 나타내는 행동 a를 선택할 수 있습니다.
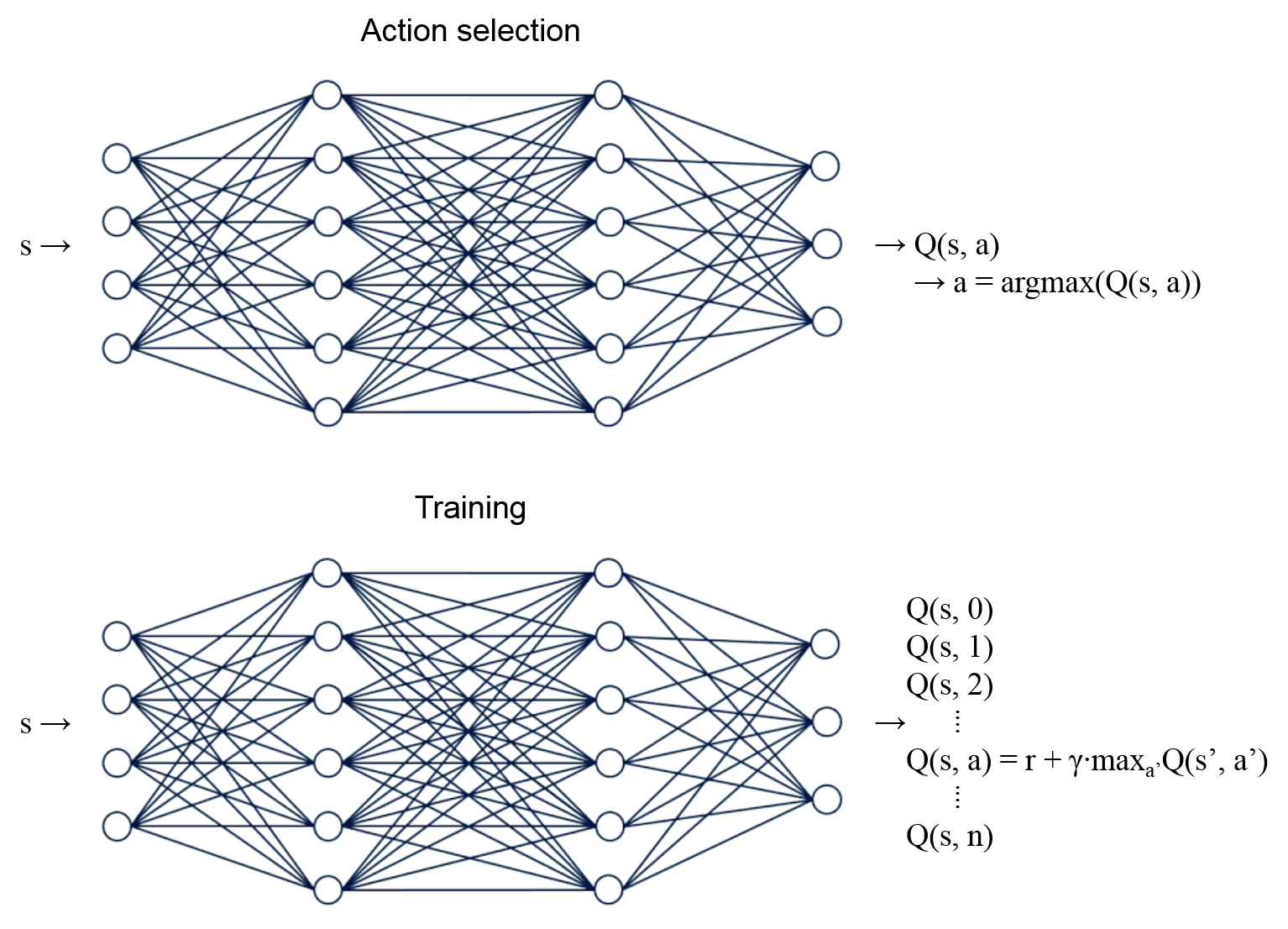
Deep Q-learning에서 행동을 선택하고, 훈련이 이루어지는 과정¶
에이전트가 행동을 선택하고 나면 (Action selection), 그 상태에서 그 행동을 취함으로써 얻는 보상이 결정됩니다. 이제 우리가 해야할 일은 두번째 그림 (Training)과 같이 Q-learning 룰에 따라 네트워크를 훈련하는 것입니다. 행동 a에 대한 Q(s, a) 값에 대해서만 \(r + \gamma Q(s', a')\) 를 목표값으로 해서 훈련이 이루어집니다.
이러한 방식으로 뉴럴 네트워크를 훈련하고 나면, 이제 출력되는 Q(s, a) 값들은 에이전트에게 그 상태에서 어떤 선택이 가장 좋은 선택인지 알려줄 수 있게 됩니다.
다음 페이지에서는 행동을 선택하는 과정에 있어서 추가적으로 필요한 \(\epsilon\)-greedy 정책에 대해 다룹니다.
이전글/다음글
이전글 : Q-learning
다음글 : Epsilon-greedy 정책