Contents
- 강화학습 시작하기 (CartPole 게임)
- 환경 (Environments)
- 관찰 (Observations)
- 공간 (Spaces)
- 첫번째 알고리즘
- 첫번째 뉴럴 네트워크
- 강화학습 (Reinforcement Learning)
- Q-learning
- Deep Q-learning
- Epsilon-greedy 정책
- 첫번째 훈련
- Epsilon의 영향
Tutorials
- Python Tutorial
- NumPy Tutorial
- Matplotlib Tutorial
- PyQt5 Tutorial
- BeautifulSoup Tutorial
- xlrd/xlwt Tutorial
- Pillow Tutorial
- Googletrans Tutorial
- PyWin32 Tutorial
- PyAutoGUI Tutorial
- Pyperclip Tutorial
- TensorFlow Tutorial
- Tips and Examples
첫번째 훈련¶
앞에서 다룬 Q-learning과 \(\epsilon\)-greedy 정책을 이용해서 뉴럴 네트워크를 훈련시켜 보겠습니다.
import gym
import tensorflow as tf
import numpy as np
import random
from collections import deque
우선 필요한 모듈을 임포트합니다.
# 뉴럴 네트워크 모델 만들기
model = tf.keras.models.Sequential([
tf.keras.layers.Dense(24, input_dim=4, activation=tf.nn.relu),
tf.keras.layers.Dense(24, activation=tf.nn.relu),
tf.keras.layers.Dense(2, activation='linear')
])
TensorFlow를 이용해서 훈련에 사용될 뉴럴 네트워크 모델을 형성합니다. 이 뉴럴 네트워크는 4개의 입력, 2개의 출력 노드를 갖습니다.
그리고 2개의 은닉층 (hidden layer)은 각각 24개의 뉴런 노드를 갖습니다.
# 모델 컴파일
model.compile(optimizer='adam',
loss='mean_squared_error',
learning_rate=0.001)
model.compile()를 이용해서 모델의 훈련 방식, 손실함수, 학습률 등을 설정합니다.
score = []
memory = deque(maxlen=2000)
# CartPole 환경 구성
env = gym.make('CartPole-v0')
score는 각 에피소드의 점수를 저장하고, memory에는 현재 상태와 행동, 다음 상태, 보상 등을 보관하게 됩니다.
maxlen=2000을 통해 memory의 길이를 2000으로 제한했습니다.
deque의 사용에 대해서는 deque로 리스트의 길이 제한하기 페이지를 참고하세요.
# 1000회의 에피소드 시작
for i in range(1000):
state = env.reset()
state = np.reshape(state, [1, 4])
eps = 1 / (i / 50 + 10)
1000회의 에피소드를 진행합니다. 각 에피소드를 시작할 때 환경을 초기화하고, 첫번째 관찰을 뉴럴 네트워크의 입력에 맞는 형태로 변환합니다.
eps는 \(\epsilon\) 값입니다. 에피소드가 진행될수록 탐색 (exploration)보다 활용 (exploitation)의 비율이 높아집니다.
자세한 내용은 Epsilon-greedy 정책 페이지를 참고하세요.
# 200 timesteps
for t in range(200):
# Inference: e-greedy
if np.random.rand() < eps:
action = np.random.randint(0, 2)
else:
predict = model.predict(state)
action = np.argmax(predict)
CartPole의 한 에피소드는 200 시간 스텝 동안 진행합니다.
각 시간 스텝에서 매번 행동을 선택 (inference)하는데, eps 값에 따라서 임의의 선택을 하거나 뉴럴 네트워크의 선택을 따르도록 합니다.
next_state, reward, done, _ = env.step(action)
next_state = np.reshape(next_state, [1, 4])
memory.append((state, action, reward, next_state, done))
state = next_state
선택한 행동 (action)에 따라 다음 상태와, 보상, done 값이 반환됩니다. (env.step(action)의 반환값)
다음 상태 (next_state)는 다시 뉴럴 네트워크에 입력하기 위해 적절한 형태로 변환합니다.
현재 상태와 행동, 다음 상태, 보상, done을 튜플의 형태로 memory에 저장한 후, 상태 (state)를 다음 상태 (next_state)로 전환합니다.
if done or t == 199:
print('Episode', i, 'Score', t + 1)
score.append(t + 1)
break
200 시간 스텝 동안 게임이 진행되거나 그전에 종료될 경우 (done==True), 점수를 저장하고, 에피소드를 종료합니다.
# Training
if i > 10:
minibatch = random.sample(memory, 16)
for state, action, reward, next_state, done in minibatch:
target = reward
if not done:
target = reward + 0.9 * np.amax(model.predict(next_state)[0])
target_outputs = model.predict(state)
target_outputs[0][action] = target
model.fit(state, target_outputs, epochs=1, verbose=0)
에피소드를 10회 이상 진행하는 경우,
Q-learning 룰에 따라 Q-값 (target)을 설정해주고, 현재 상태 (state)에서 뉴럴 네트워크가 출력해야할 값들 (target_outputs)을 설정합니다.
model.fit()을 이용해서 훈련을 진행합니다.
env.close()
print(score)
환경을 종료하고, 에피소드에 따른 점수를 출력합니다.
결과는 아래와 같습니다. 실력이 서서히 향상되는 것을 알 수 있습니다.
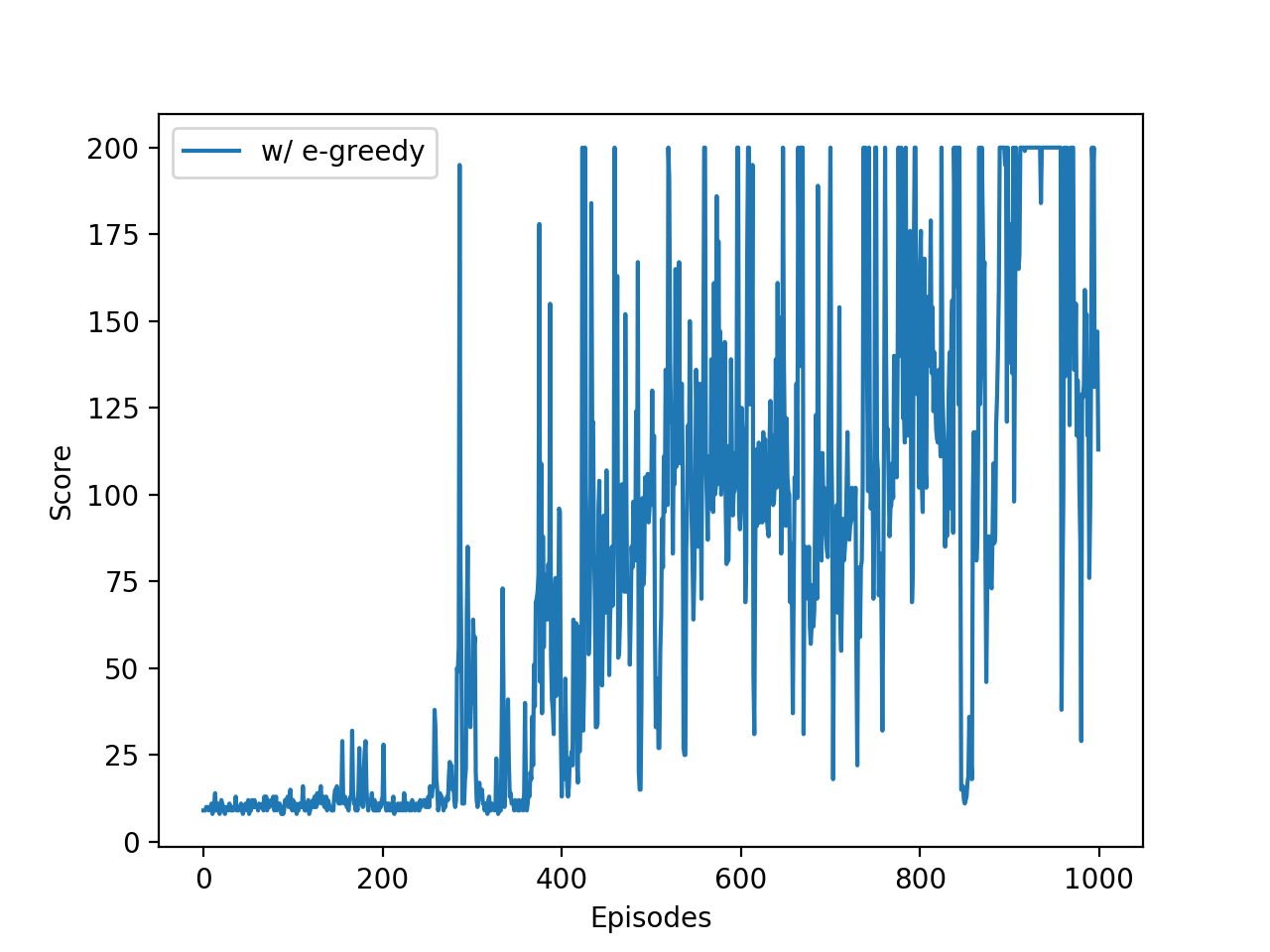
CartPole 게임의 에피소드에 따른 점수.¶
1000회의 에피소드 이후, 카트의 움직임은 아래의 영상과 같습니다.
전체 코드는 아래와 같습니다.
import gym
import tensorflow as tf
import numpy as np
import random
from collections import deque
# 뉴럴 네트워크 모델 만들기
model = tf.keras.models.Sequential([
tf.keras.layers.Dense(24, input_dim=4, activation=tf.nn.relu),
tf.keras.layers.Dense(24, activation=tf.nn.relu),
tf.keras.layers.Dense(2, activation='linear')
])
# 모델 컴파일
model.compile(optimizer='adam',
loss='mean_squared_error',
learning_rate=0.001)
score = []
memory = deque(maxlen=2000)
# CartPole 환경 구성
env = gym.make('CartPole-v0')
# 1000회의 에피소드 시작
for i in range(1000):
state = env.reset()
state = np.reshape(state, [1, 4])
eps = 1 / (i / 50 + 10)
# 200 timesteps
for t in range(200):
# Inference: e-greedy
if np.random.rand() < eps:
action = np.random.randint(0, 2)
else:
predict = model.predict(state)
action = np.argmax(predict)
next_state, reward, done, _ = env.step(action)
next_state = np.reshape(next_state, [1, 4])
memory.append((state, action, reward, next_state, done))
state = next_state
if done or t == 199:
print('Episode', i, 'Score', t + 1)
score.append(t + 1)
break
# Training
if i > 10:
minibatch = random.sample(memory, 16)
for state, action, reward, next_state, done in minibatch:
target = reward
if not done:
target = reward + 0.9 * np.amax(model.predict(next_state)[0])
target_outputs = model.predict(state)
target_outputs[0][action] = target
model.fit(state, target_outputs, epochs=1, verbose=0)
env.close()
print(score)