Contents
- 강화학습 시작하기 (CartPole 게임)
- 환경 (Environments)
- 관찰 (Observations)
- 공간 (Spaces)
- 첫번째 알고리즘
- 첫번째 뉴럴 네트워크
- 강화학습 (Reinforcement Learning)
- Q-learning
- Deep Q-learning
- Epsilon-greedy 정책
- 첫번째 훈련
- Epsilon의 영향
Tutorials
- Python Tutorial
- NumPy Tutorial
- Matplotlib Tutorial
- PyQt5 Tutorial
- BeautifulSoup Tutorial
- xlrd/xlwt Tutorial
- Pillow Tutorial
- Googletrans Tutorial
- PyWin32 Tutorial
- PyAutoGUI Tutorial
- Pyperclip Tutorial
- TensorFlow Tutorial
- Tips and Examples
첫번째 뉴럴 네트워크¶
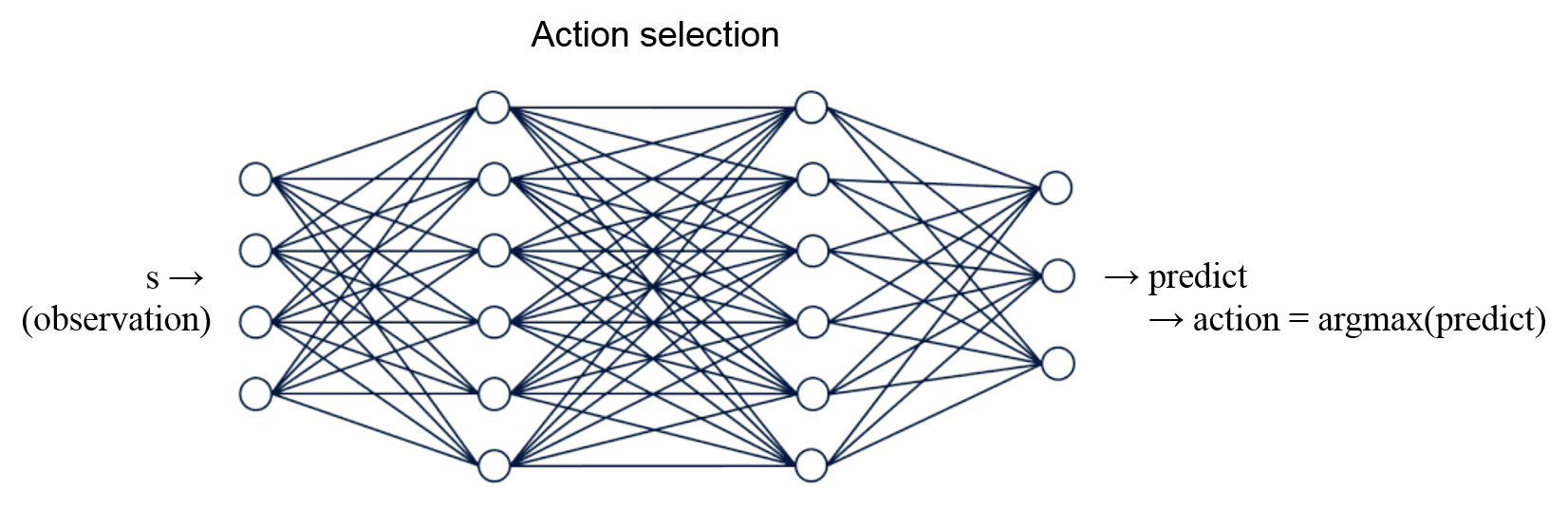
뉴럴 네트워크를 이용한 행동의 선택.¶
뉴럴 네트워크를 사용해서 현재 상태에 대한 행동을 선택하도록 하고,
CartPole 게임을 더 잘하도록 이 뉴럴 네트워크를 훈련할 수 있습니다.
우선 TensorFlow 를 이용해서 가장 간단한 형태의 뉴럴 네트워크를 구성합니다.
예제1 - 뉴럴 네트워크의 선택¶
import gym
import tensorflow as tf
import numpy as np
# CartPole 환경 구성
env = gym.make('CartPole-v0')
# 뉴럴 네트워크 모델 만들기
model = tf.keras.models.Sequential([
tf.keras.layers.Dense(128, input_shape=(4,), activation=tf.nn.relu),
tf.keras.layers.Dense(2)
])
# 첫번째 관찰
observation = env.reset()
# 뉴럴 네트워크의 선택
predict = model.predict(observation.reshape(1, 4))
action = np.argmax(predict)
print(observation)
print(predict)
print(action)
[[-0.02922633 0.01323094 0.04069413 0.01289527]]
[[ 0.00087276 -0.00441547]]
0
tf.keras.models.Sequential() 을 이용해서 4개의 입력을 받고, 2개의 값을 출력하는 뉴럴 네트워크를 구성했습니다.
은닉층 (hidden layer)의 노드의 개수는 128개입니다.
출력되는 결과를 보면, 첫번째 관찰은 [-0.02922633 0.01323094 0.04069413 0.01289527]임을 알 수 있습니다.
그리고 뉴럴 네트워크가 출력하는 값은 [ 0.00087276 -0.00441547]이고, 따라서 더 큰 값에 해당하는 행동 0을 선택하게 됩니다.
지금은 임의의 웨이트 (뉴런 노드 간의 연결 강도) 값을 갖는 뉴럴 네트워크이기 때문에 선택도 아무런 의미가 없습니다.
예제2 - 100회의 에피소드 반복¶
import gym
import tensorflow as tf
import numpy as np
# CartPole 환경 구성
env = gym.make('CartPole-v0')
# 뉴럴 네트워크 모델 만들기
model = tf.keras.models.Sequential([
tf.keras.layers.Dense(128, input_shape=(4,), activation=tf.nn.relu),
tf.keras.layers.Dense(2)
])
score = []
# 100회의 에피소드
for i in range(100):
observation = env.reset()
# 200개의 시간 스텝
for t in range(200):
# 뉴럴 네트워크의 선택
predict = model.predict(observation.reshape(1, 4))
action = np.argmax(predict)
observation, reward, done, info = env.step(action)
if done:
score.append(t + 1)
break
env.close()
print(score)
[31, 8, 9, 10, 9, 10, 10, 13, 13, 10, 10, 27, 13, 10, 8, 10, 11, 38, 9, 15, 15, 10, 10, 9, 10, 9, 9, 9, 10, 10, 10, 9, 10, 10, 27, 9, 8, 10, 24, 10, 10, 10, 8, 10, 9, 9, 9, 10, 10, 13, 39, 11, 9, 23, 10, 10, 9, 10, 8, 10, 10, 9, 10, 11, 9, 17, 10, 12, 9, 9, 9, 9, 10, 28, 10, 10, 10, 9, 10, 9, 10, 12, 10, 9, 8, 12, 10, 15, 10, 10, 9, 8, 9, 9, 17, 9, 10, 10, 10, 10]
뉴럴 네트워크가 선택하는 과정을 100회의 에피소드, 그리고 각 에피소드에서 200개의 시간 스텝 동안 실행했습니다.
출력되는 결과 (score)는 각 에피소드가 종료될 때까지 유지한 시간 스텝을 의미합니다.
아래의 그림과 같이 에피소드가 진행되어도 실력이 향상되지 않음을 알 수 있습니다.
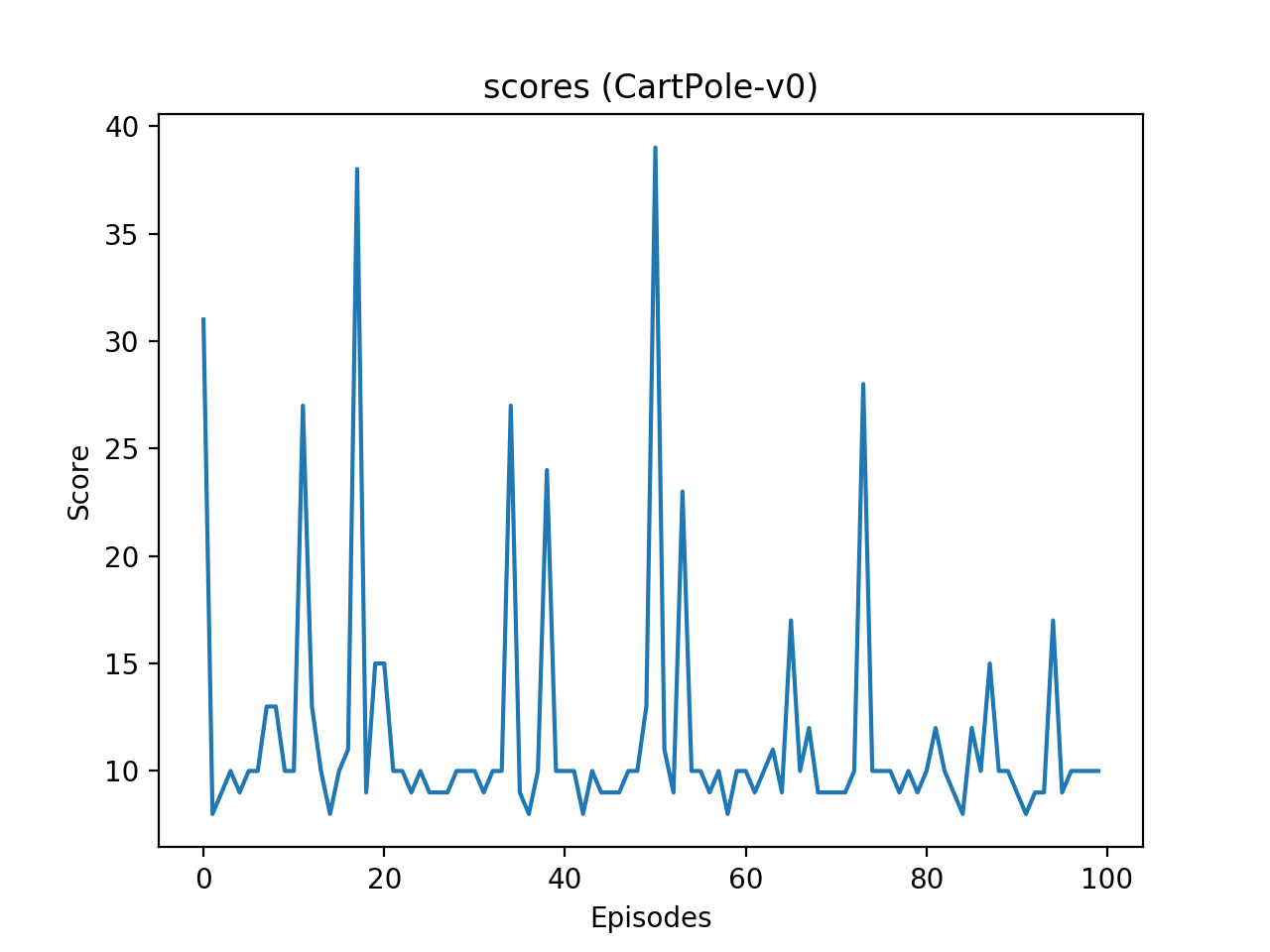
CartPole 게임의 에피소드에 따른 점수.¶
이전글/다음글
이전글 : 첫번째 알고리즘