Contents
- TF-Agents 모듈 임포트하기
- TF-Agents 환경 준비하기
- TF-Agents 환경 살펴보기
- TF-Agents 행동 반영하기
- TF-Agents 환경 Wrapper 사용하기
- TF-Agents 에이전트 구성하기
- TF-Agents 정책 다루기
- TF-Agents 정책 평가하기
- TF-Agents 데이터 수집하기
- TF-Agents 에이전트 훈련하기
Tutorials
- Python Tutorial
- NumPy Tutorial
- Matplotlib Tutorial
- PyQt5 Tutorial
- BeautifulSoup Tutorial
- xlrd/xlwt Tutorial
- Pillow Tutorial
- Googletrans Tutorial
- PyWin32 Tutorial
- PyAutoGUI Tutorial
- Pyperclip Tutorial
- TensorFlow Tutorial
- Tips and Examples
TF-Agents 환경 Wrapper 사용하기¶
지금까지 소개한 강화학습 환경은 Python 기반의 환경이었습니다.
Python 기반의 환경을 TensorFlow 환경으로 포장 (Wrap)하면, 배열 (Array) 대신 텐서 (Tensor)를 사용하고 TensorFlow가 작업을 병렬화할 수 있도록 합니다.
이 페이지에서는 TF-Agents의 Python 환경을 TensorFlow 환경으로 포장 (Wrap)하는 방법에 대해 소개합니다.
■ Table of Contents
1) TFPyEnvironment Wrapper 사용하기¶
예제1¶
from tf_agents.environments import suite_gym
from tf_agents.environments import tf_py_environment
env_name = 'CartPole-v0'
env = suite_gym.load(env_name)
tf_env = tf_py_environment.TFPyEnvironment(env)
print(tf_env)
print(isinstance(tf_env, tf_py_environment.TFPyEnvironment))
<tf_agents.environments.tf_py_environment.TFPyEnvironment object at 0x7f674688fe48>
True
Python 기반의 환경을 tf_py_environment.TFPyEnvironment Wrapper를 사용해서 TensorFlow 환경으로 포장했습니다.
이제 tf_env는 tf_py_environment.TFPyEnvironment의 인스턴스임을 알 수 있습니다.

예제2¶
print(env.time_step_spec())
print(env.action_spec())
print(tf_env.time_step_spec())
print(tf_env.action_spec())
TimeStep(step_type=ArraySpec(shape=(), dtype=dtype('int32'), name='step_type'), reward=ArraySpec(shape=(), dtype=dtype('float32'), name='reward'), discount=BoundedArraySpec(shape=(), dtype=dtype('float32'), name='discount', minimum=0.0, maximum=1.0), observation=BoundedArraySpec(shape=(4,), dtype=dtype('float32'), name='observation', minimum=[-4.8000002e+00 -3.4028235e+38 -4.1887903e-01 -3.4028235e+38], maximum=[4.8000002e+00 3.4028235e+38 4.1887903e-01 3.4028235e+38]))
BoundedArraySpec(shape=(), dtype=dtype('int64'), name='action', minimum=0, maximum=1)
TimeStep(step_type=TensorSpec(shape=(), dtype=tf.int32, name='step_type'), reward=TensorSpec(shape=(), dtype=tf.float32, name='reward'), discount=BoundedTensorSpec(shape=(), dtype=tf.float32, name='discount', minimum=array(0., dtype=float32), maximum=array(1., dtype=float32)), observation=BoundedTensorSpec(shape=(4,), dtype=tf.float32, name='observation', minimum=array([-4.8000002e+00, -3.4028235e+38, -4.1887903e-01, -3.4028235e+38],
dtype=float32), maximum=array([4.8000002e+00, 3.4028235e+38, 4.1887903e-01, 3.4028235e+38],
dtype=float32)))
BoundedTensorSpec(shape=(), dtype=tf.int64, name='action', minimum=array(0), maximum=array(1))
Python 환경과 TensorFlow 환경의 TimeStep과 Action의 사양을 출력했습니다.
ArraySpec과 BoundedArraySpec이 TensorSpec과 BoundedTensorSpec으로 변환된 것을 알 수 있습니다.

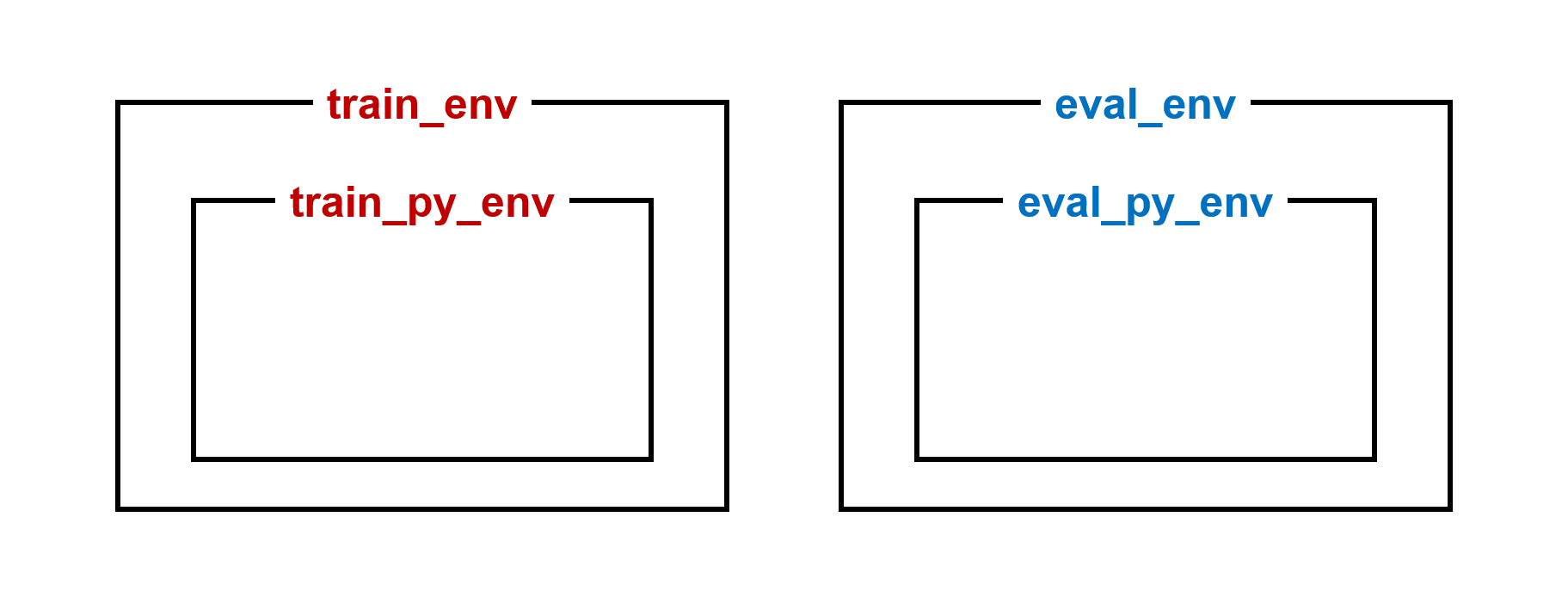
2) 훈련용, 검증용 환경 생성하기¶
예제¶
from tf_agents.environments import suite_gym
from tf_agents.environments import tf_py_environment
env_name = 'CartPole-v0'
train_py_env = suite_gym.load(env_name)
eval_py_env = suite_gym.load(env_name)
train_env = tf_py_environment.TFPyEnvironment(train_py_env)
eval_env = tf_py_environment.TFPyEnvironment(eval_py_env)
print(train_env)
print(eval_env)
<tf_agents.environments.tf_py_environment.TFPyEnvironment object at 0x7f6744580f28>
<tf_agents.environments.tf_py_environment.TFPyEnvironment object at 0x7f6744580d30>
일반적으로 훈련용, 검증용 두 개의 환경이 인스턴스화됩니다.
순수 Python으로 작성된 CartPole 게임 환경을 TFPyEnvironment Wrapper를 사용해서 TensorFlow 환경으로 포장했습니다.
이전글/다음글
이전글 : TF-Agents 행동 반영하기
다음글 : TF-Agents 에이전트 구성하기