Contents
- TF-Agents 모듈 임포트하기
- TF-Agents 환경 준비하기
- TF-Agents 환경 살펴보기
- TF-Agents 행동 반영하기
- TF-Agents 환경 Wrapper 사용하기
- TF-Agents 에이전트 구성하기
- TF-Agents 정책 다루기
- TF-Agents 정책 평가하기
- TF-Agents 데이터 수집하기
- TF-Agents 에이전트 훈련하기
Tutorials
- Python Tutorial
- NumPy Tutorial
- Matplotlib Tutorial
- PyQt5 Tutorial
- BeautifulSoup Tutorial
- xlrd/xlwt Tutorial
- Pillow Tutorial
- Googletrans Tutorial
- PyWin32 Tutorial
- PyAutoGUI Tutorial
- Pyperclip Tutorial
- TensorFlow Tutorial
- Tips and Examples
TF-Agents 에이전트 훈련하기¶
TF-Agents 훈련에서는 우선 환경으로부터 데이터를 수집하고, 에이전트의 신경망을 훈련하는 과정이 이루어집니다.
이번에는 에이전트의 훈련이 이루어지는 과정과, Matplotlib을 이용해서 시각화하는 방법을 소개합니다.
■ Table of Contents
1) 에이전트 훈련하기¶
예제¶
import tensorflow as tf
from tf_agents.environments import suite_gym
from tf_agents.environments import tf_py_environment
from tf_agents.agents.dqn import dqn_agent
from tf_agents.networks import q_network
from tf_agents.utils import common
from tf_agents.policies import random_tf_policy
from tf_agents.replay_buffers import tf_uniform_replay_buffer
from tf_agents.trajectories import trajectory
env_name = 'CartPole-v0'
train_py_env = suite_gym.load(env_name)
eval_py_env = suite_gym.load(env_name)
train_env = tf_py_environment.TFPyEnvironment(train_py_env)
eval_env = tf_py_environment.TFPyEnvironment(eval_py_env)
q_net = q_network.QNetwork(
train_env.observation_spec(),
train_env.action_spec(),
fc_layer_params=(100,))
optimizer = tf.compat.v1.train.AdamOptimizer(learning_rate=1e-3)
train_step_counter = tf.Variable(0)
agent = dqn_agent.DqnAgent(
train_env.time_step_spec(),
train_env.action_spec(),
q_network=q_net,
optimizer=optimizer,
td_errors_loss_fn=common.element_wise_squared_loss,
train_step_counter=train_step_counter)
agent.initialize()
eval_policy = agent.policy
collect_policy = agent.collect_policy
random_policy = random_tf_policy.RandomTFPolicy(train_env.time_step_spec(),
train_env.action_spec())
def compute_avg_return(environment, policy, num_episodes=10):
total_return = 0.0
for _ in range(num_episodes):
time_step = environment.reset()
episode_return = 0.0
while not time_step.is_last():
action_step = policy.action(time_step)
time_step = environment.step(action_step.action)
episode_return += time_step.reward
total_return += episode_return
avg_return = total_return / num_episodes
return avg_return.numpy()[0]
replay_buffer_max_length = 100000
replay_buffer = tf_uniform_replay_buffer.TFUniformReplayBuffer(
data_spec=agent.collect_data_spec,
batch_size=train_env.batch_size,
max_length=replay_buffer_max_length)
def collect_step(environment, policy, buffer):
time_step = environment.current_time_step()
action_step = policy.action(time_step)
next_time_step = environment.step(action_step.action)
traj = trajectory.from_transition(time_step, action_step, next_time_step)
buffer.add_batch(traj)
def collect_data(env, policy, buffer, steps):
for _ in range(steps):
collect_step(env, policy, buffer)
initial_collect_steps = 100
collect_data(train_env, random_policy, replay_buffer, initial_collect_steps)
dataset = replay_buffer.as_dataset(
num_parallel_calls=3,
sample_batch_size=64,
num_steps=2).prefetch(3)
iterator = iter(dataset)
# Hyperparameter
num_iterations = 20000
collect_steps_per_iteration = 1
log_interval = 200
num_eval_episodes = 10
eval_interval = 1000
# Training Agent
agent.train = common.function(agent.train)
agent.train_step_counter.assign(0)
avg_return = compute_avg_return(eval_env, agent.policy, num_eval_episodes)
returns = [avg_return]
for _ in range(num_iterations):
collect_data(train_env, agent.collect_policy, replay_buffer, collect_steps_per_iteration)
experience, unused_info = next(iterator)
train_loss = agent.train(experience).loss
step = agent.train_step_counter.numpy()
if step % log_interval == 0:
print('step = {0}: loss = {1}'.format(step, train_loss))
if step % eval_interval == 0:
avg_return = compute_avg_return(eval_env, agent.policy, num_eval_episodes)
print('step = {0}: Average Return = {1}'.format(step, avg_return))
returns.append(avg_return)
step = 200: loss = 15.965837478637695
step = 400: loss = 30.888050079345703
step = 600: loss = 24.413467407226562
step = 800: loss = 14.003098487854004
step = 1000: loss = 13.397834777832031
step = 1000: Average Return = 18.200000762939453
step = 1200: loss = 26.596389770507812
step = 1400: loss = 23.81806182861328
step = 1600: loss = 21.07032012939453
step = 1800: loss = 44.38041687011719
step = 2000: loss = 9.118896484375
step = 2000: Average Return = 39.900001525878906
...
step = 18000: loss = 11.91856575012207
step = 18000: Average Return = 200.0
step = 18200: loss = 46.057838439941406
step = 18400: loss = 28.486873626708984
step = 18600: loss = 1671.150634765625
step = 18800: loss = 2060.869384765625
step = 19000: loss = 3103.8408203125
step = 19000: Average Return = 200.0
step = 19200: loss = 34.38957214355469
step = 19400: loss = 812.089111328125
step = 19600: loss = 3772.72802734375
step = 19800: loss = 28.619001388549805
step = 20000: loss = 53.242431640625
step = 20000: Average Return = 200.0
TF-Agents 데이터 수집하기 페이지에서 작성한 코드에 이어서 에이전트 훈련을 위한 코드를 작성합니다.
우선 하이퍼파라미터 (Hyperparameter)를 지정합니다.
num_iterations은 전체 훈련 횟수입니다.
collect_steps_per_iteration는 한 훈련 당 몇 회의 데이터 수집을 할지를 지정합니다.
log_interval는 훈련 과정 중 로그를 출력할 간격을 지정합니다.
num_eval_episodes는 평균 보상을 계산할 에피소드의 개수를 지정합니다.
eval_interval는 훈련 과정 중 검증을 수행할 간격을 지정합니다.
훈련 과정은 collect_data() 함수를 사용해서 데이터를 수집하는 것으로 시작합니다.
데이터셋으로부터 훈련용 데이터를 얻고 train() 메서드를 사용해서 훈련을 진행합니다.
log_interval과 eval_interval마다 손실값 (loss)과 평균 리턴값이 출력됩니다.
파이썬 문자열 format() 메서드의 사용에 대해서는 이 페이지를 참고하세요.
2) 훈련 과정 시각화하기¶
예제¶
import matplotlib.pyplot as plt
iterations = range(0, num_iterations + 1, eval_interval)
plt.xlabel('Iterations')
plt.ylabel('Average Return')
plt.ylim(top=250)
plt.plot(iterations, returns)
plt.show()
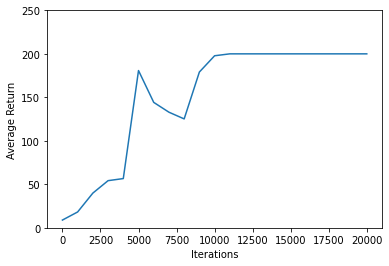
Matplotlib 라이브러리를 사용해서 훈련 과정에서 얻은 평균 리턴을 시각화할 수 있습니다.
plt.plot() 함수는 기본적으로 두 개의 x, y 데이터를 꺾은선 그래프로 형태로 시각화합니다.
아래와 같은 그래프가 나타납니다.
약 10,000회 훈련부터 200회의 평균 리턴을 얻고 있고, 즉 CartPole-v0 게임을 해결했음을 확인할 수 있습니다.