Contents
- Pandas Tutorial - 파이썬 데이터 분석 라이브러리
- Pandas 객체 생성하기 (Object creation)
- Pandas 데이터 보기 (Viewing data)
- Pandas 데이터 선택하기 (Selection)
- Pandas 누락된 데이터 (Missing data)
- Pandas 연산 (Operations)
- Pandas 병합하기 (Merge)
- Pandas 그룹 (Grouping)
- Pandas 형태 바꾸기 (Reshaping)
- Pandas 타임 시리즈 (Time series)
Tutorials
- Python Tutorial
- NumPy Tutorial
- Matplotlib Tutorial
- PyQt5 Tutorial
- BeautifulSoup Tutorial
- xlrd/xlwt Tutorial
- Pillow Tutorial
- Googletrans Tutorial
- PyWin32 Tutorial
- PyAutoGUI Tutorial
- Pyperclip Tutorial
- TensorFlow Tutorial
- Tips and Examples
Pandas 객체 생성하기 (Object creation)¶
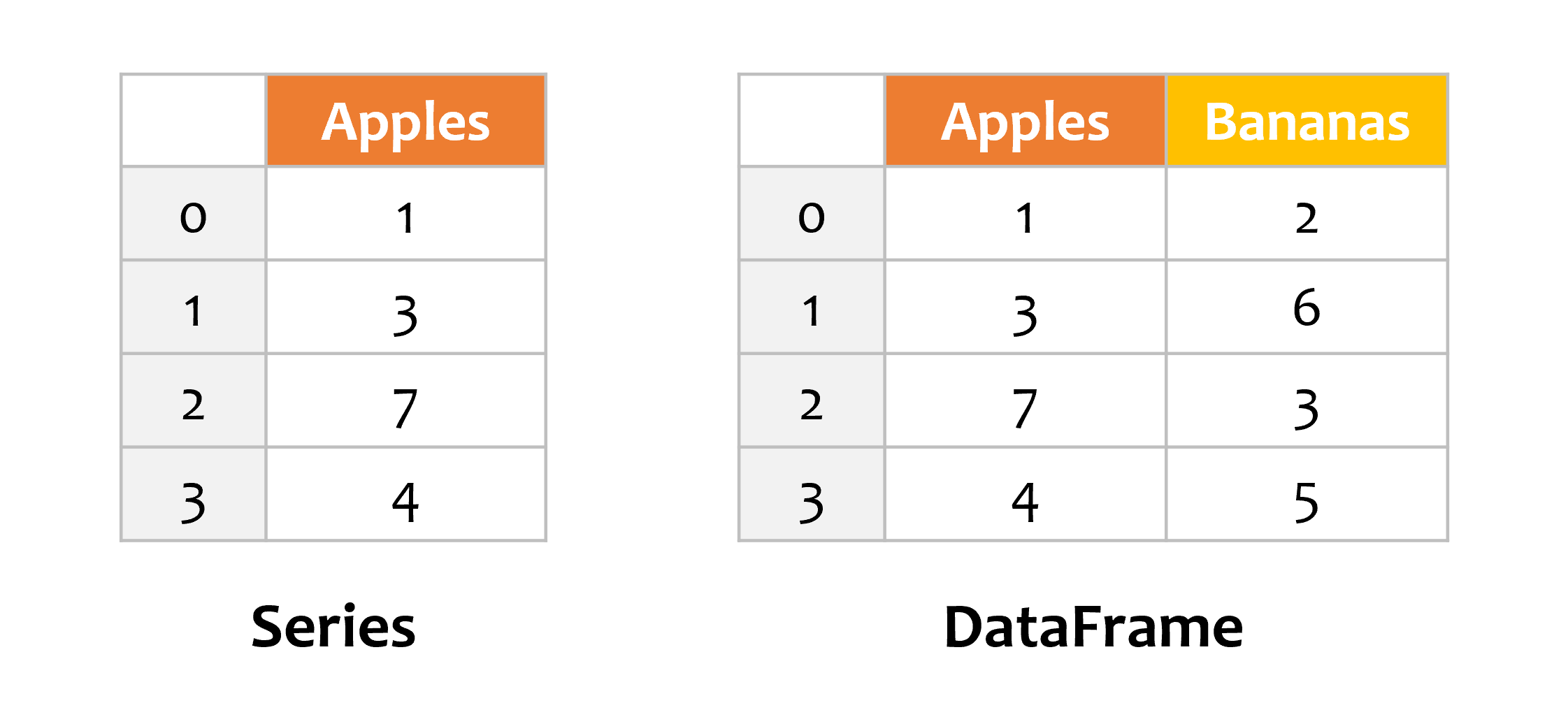
Pandas의 기본 객체인 Series와 DataFrame을 생성하는 다양한 방법에 대해 알아봅니다.
Series: 레이블을 갖는 1차원 어레이
DataFrame: 레이블을 갖는 행과 열을 갖는 2차원 어레이
◼︎ Table of Contents
1) Series와 DataFrame¶
Series는 다양한 자료형을 담을 수 있는 1차원의 어레이이며, 엑셀 문서의 하나의 열 (column)과 같습니다.
Series는 Index라고 하는 레이블을 가집니다.

DataFrame은 행과 열을 갖는 2차원의 자료형입니다. 여러 개의 Series가 모이면 DataFrame을 구성할 수 있습니다.
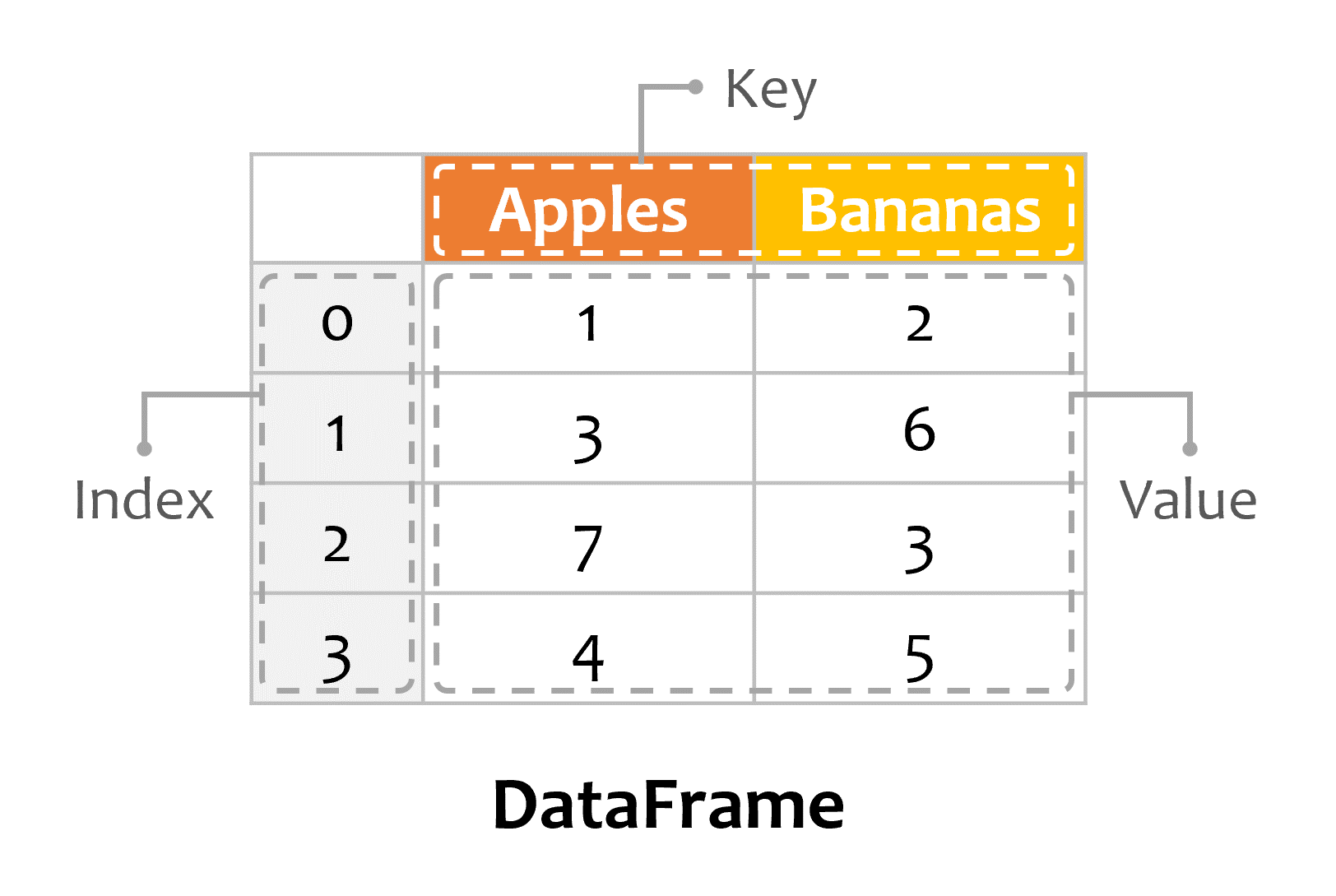
그림과 같이 DataFrame은 Index와 Key, 그리고 Value들로 구성됩니다.
2) Series 만들기¶
예제1 - 정수형 Series¶
import pandas as pd
s = pd.Series([1, 3, 5, 4, 6, 8])
print(s)
0 1
1 3
2 5
3 4
4 6
5 8
dtype: int64
정수 자료형의 Series를 하나 만들었습니다.
Series()에 값들의 리스트를 입력해서 Series를 만들면, Pandas가 정수 인덱스를 자동으로 만들어줍니다.
예제2 - 실수형 Series¶
import pandas as pd
s = pd.Series([1, 3.5, 5, 4, 6.2, 8])
print(s)
0 1.0
1 3.5
2 5.0
3 4.0
4 6.2
5 8.0
dtype: float64
정수와 실수가 함께 있는 리스트를 입력하면 두 자료형을 모두 표현할 수 있는 실수 자료형의 Series가 하나 만들어집니다.
예제3 - 인덱스 지정하기¶
import pandas as pd
s = pd.Series([1, 3.5, 5, 4, 6.2, 8], index=['a', 'b', 'c', 'd', 'e', 'f'])
print(s)
a 1.0
b 3.5
c 5.0
d 4.0
e 6.2
f 8.0
dtype: float64
Series()의 index 키워드를 사용해서 인덱스를 자유롭게 설정할 수 있습니다.
3) DataFrame 만들기¶
예제1 - NumPy 어레이로 만들기¶
import pandas as pd
import numpy as np
dates = pd.date_range('20130101', periods=6)
df = pd.DataFrame(np.random.randn(6, 4), index=dates, columns=list('ABCD'))
print(dates)
print(df)
DatetimeIndex(['2013-01-01', '2013-01-02', '2013-01-03', '2013-01-04',
'2013-01-05', '2013-01-06'],
dtype='datetime64[ns]', freq='D')
A B C D
2013-01-01 -0.221506 -1.252301 0.049855 -1.173173
2013-01-02 -0.299313 -1.753844 0.858982 1.006282
2013-01-03 -0.627516 0.791134 1.262370 -0.414763
2013-01-04 0.053944 0.610720 -0.594344 1.301093
2013-01-05 -1.634639 -0.200335 1.106788 0.225533
2013-01-06 2.164460 1.245787 -1.105391 -0.541923
날짜 인덱스와 레이블이 지정된 열이 있는 NumPy 어레이를 전달함으로써 DataFrame을 만들 수 있습니다.
date_range() 함수를 사용해서 ‘20130101’를 시작으로 하는 6개의 DatetimeIndex를 만들었습니다.
각 날짜마다 A, B, C, D열에 해당하는 난수 데이터의 DataFrame이 만들어졌습니다.
예제2 - 딕셔너리로 만들기¶
import pandas as pd
import numpy as np
df2 = pd.DataFrame({'A': 1.,
'B': pd.Timestamp('20130102'),
'C': pd.Series(1, index=list(range(4)), dtype='float32'),
'D': np.array([3] * 4, dtype='int32'),
'E': pd.Categorical(["test", "train", "test", "train"]),
'F': 'foo'})
print(df2)
print(df2.dtypes)
A B C D E F
0 1.0 2013-01-02 1.0 3 test foo
1 1.0 2013-01-02 1.0 3 train foo
2 1.0 2013-01-02 1.0 3 test foo
3 1.0 2013-01-02 1.0 3 train foo
A float64
B datetime64[ns]
C float32
D int32
E category
F object
dtype: object
Series와 같이 변환될 수 있는 객체의 딕셔너리를 전달함으로써 DataFrame을 생성할 수 있습니다.
딕셔너리의 키가 그대로 DataFrame의 키가 됩니다.
그 결과로 만들어지는 DataFrame의 열 (column)은 서로 다른 자료형 (dtypes)을 갖습니다.
4) csv 활용하기¶
csv 파일의 데이터를 DataFrame으로 불러올 수 있습니다.
우선 아래와 같은 데이터가 있는 csv 파일을 준비합니다.

예제1 - header=None¶
import pandas as pd
df1 = pd.read_csv('pandas_ex01.csv', header=None)
print(df1)
0 1
0 a 1
1 b 2
2 c 3
3 d 4
read_csv()에 csv 파일을 입력하면, DataFrame을 반환합니다.
header=None과 같이 설정하면 자동으로 생성됩니다.
예제2 - 헤더 지정하기¶
import pandas as pd
df2 = pd.read_csv('pandas_ex02.csv', header=0)
print(df2)
string number
0 a 1
1 b 2
2 c 3
3 d 4
csv 파일의 데이터가 열의 이름으로 사용할 헤더를 포함하는 경우에는 지정할 행의 번호를 입력해줄 수 있습니다.
헤더의 번호를 지정해주지 않으면 header=0과 같습니다.
예제3 - 인덱스 지정하기¶
import pandas as pd
df3 = pd.read_csv('pandas_ex02.csv', index_col=0)
print(df3)
number
string
a 1
b 2
c 3
d 4
index_col는 인덱스로 사용할 열을 지정하도록 합니다.
index_col=0으로 지정해서 첫번째 열이 인덱스가 되었습니다.