Contents
- Pandas Tutorial - 파이썬 데이터 분석 라이브러리
- Pandas 객체 생성하기 (Object creation)
- Pandas 데이터 보기 (Viewing data)
- Pandas 데이터 선택하기 (Selection)
- Pandas 누락된 데이터 (Missing data)
- Pandas 연산 (Operations)
- Pandas 병합하기 (Merge)
- Pandas 그룹 (Grouping)
- Pandas 형태 바꾸기 (Reshaping)
- Pandas 타임 시리즈 (Time series)
Tutorials
- Python Tutorial
- NumPy Tutorial
- Matplotlib Tutorial
- PyQt5 Tutorial
- BeautifulSoup Tutorial
- xlrd/xlwt Tutorial
- Pillow Tutorial
- Googletrans Tutorial
- PyWin32 Tutorial
- PyAutoGUI Tutorial
- Pyperclip Tutorial
- TensorFlow Tutorial
- Tips and Examples
Pandas 데이터 선택하기 (Selection)¶

Pandas DataFrame로부터 데이터를 선택하는 방법에 대해 알아봅니다.
순서는 아래와 같습니다.
◼︎ Table of Contents
Note
데이터를 선택하고 설정하는데 있어서 표준 Python/NumPy의 표현들이 직관적이고 작업에 편리하지만, pandas의 최적화된 데이터 접근 방식인 .at, .iat, .loc, .iloc의 사용을 권장합니다.
1) DataFrame 만들기¶
예제¶
import pandas as pd
import numpy as np
np.random.seed(0)
dates = pd.date_range('20130101', periods=6)
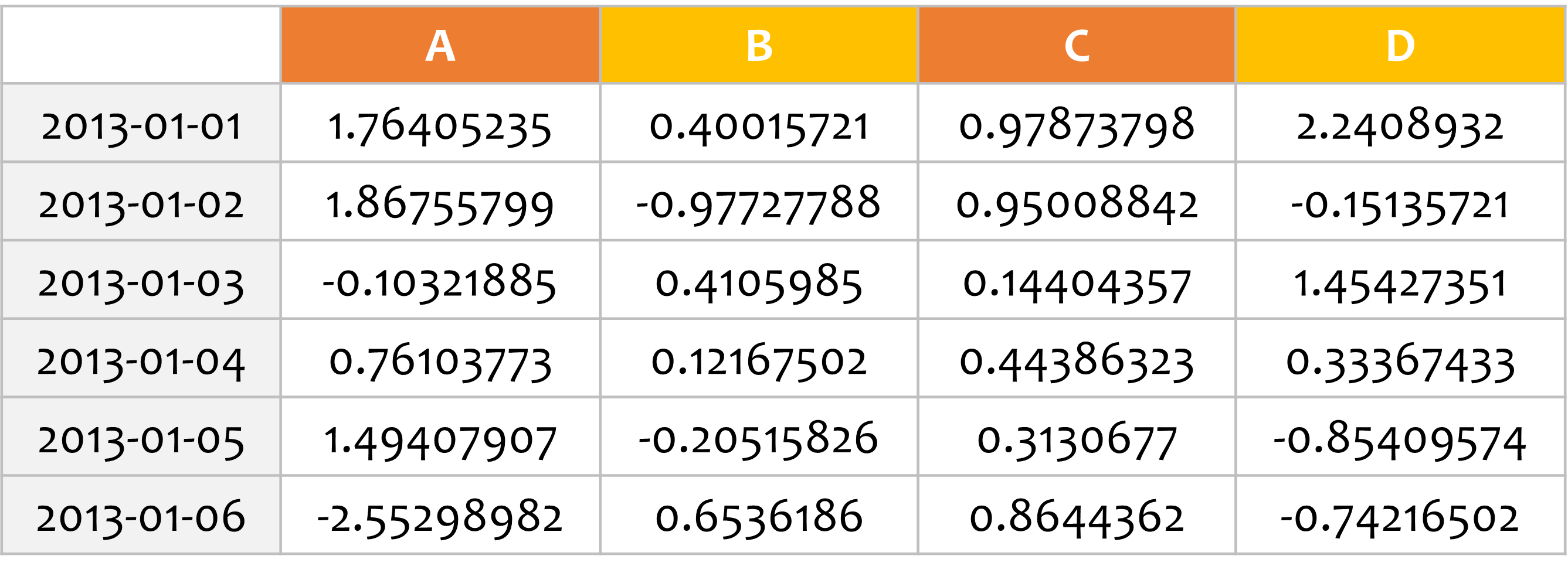
df = pd.DataFrame(np.random.randn(6, 4), index=dates, columns=list('ABCD'))
print(df)
A B C D
2013-01-01 1.764052 0.400157 0.978738 2.240893
2013-01-02 1.867558 -0.977278 0.950088 -0.151357
2013-01-03 -0.103219 0.410599 0.144044 1.454274
2013-01-04 0.761038 0.121675 0.443863 0.333674
2013-01-05 1.494079 -0.205158 0.313068 -0.854096
2013-01-06 -2.552990 0.653619 0.864436 -0.742165
우선 DataFrame 객체를 하나 만들었습니다.
2) 열 선택하기¶
예제¶
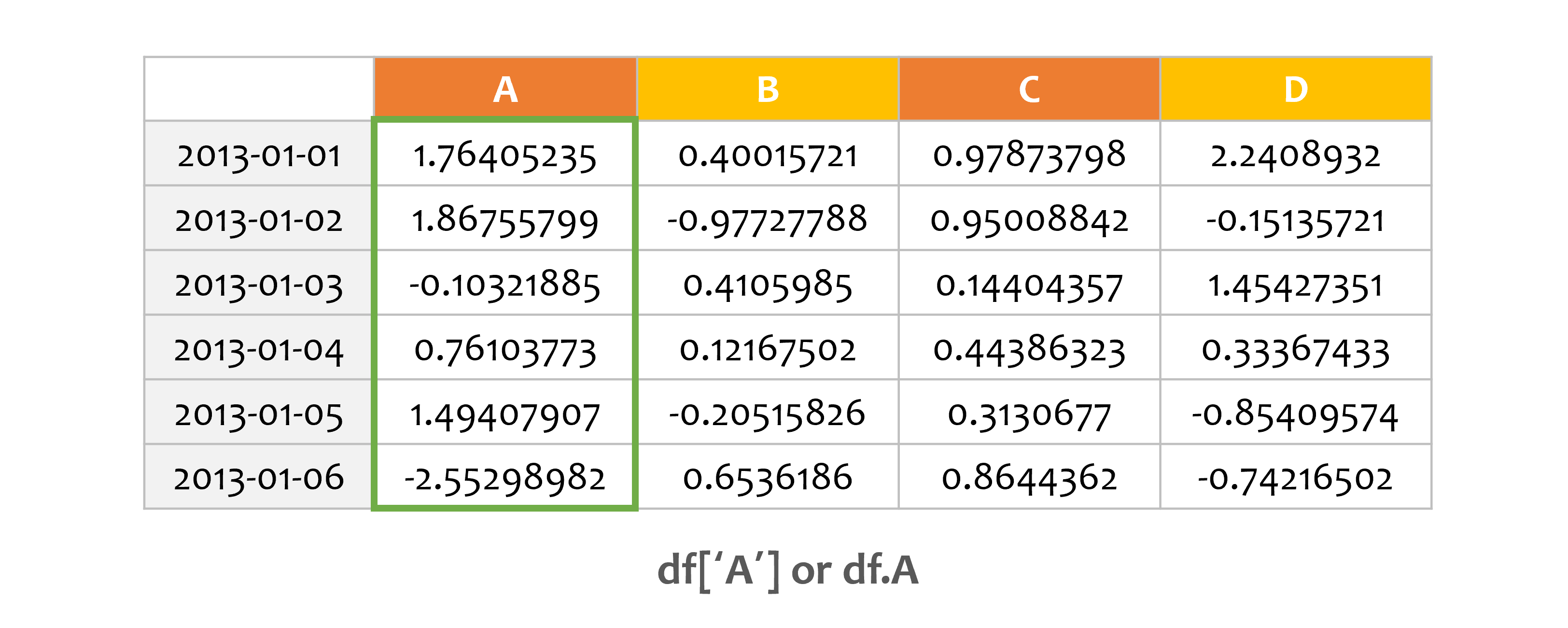
print(df['A'])
#print(df.A)
print(type(df['A']))
#print(type(df.A))
2013-01-01 1.764052
2013-01-02 1.867558
2013-01-03 -0.103219
2013-01-04 0.761038
2013-01-05 1.494079
2013-01-06 -2.552990
Freq: D, Name: A, dtype: float64
<class 'pandas.core.series.Series'>
DataFrame의 하나의 열을 선택하면, 하나의 Series를 만듭니다.
df[‘A’]는 df.A와 같습니다.
3) 행 선택하기¶
예제1¶
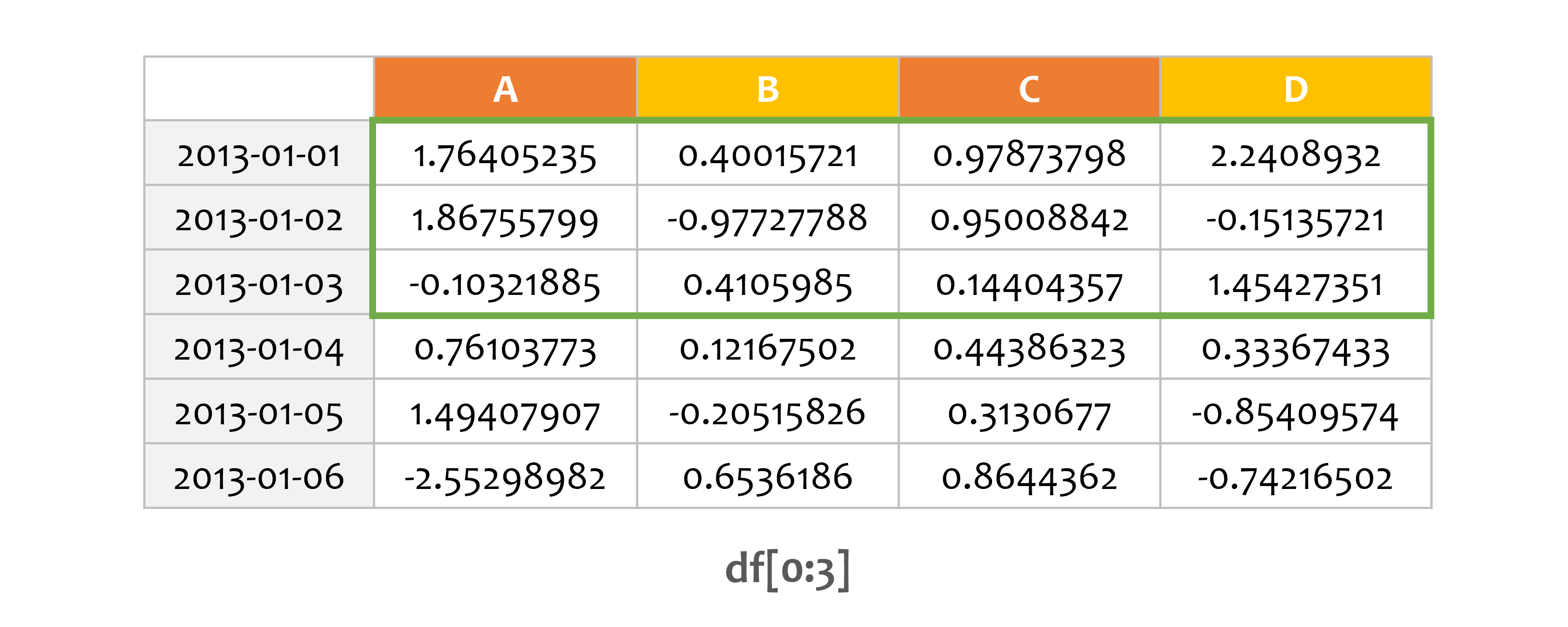
print(df[0:3])
A B C D
2013-01-01 1.764052 0.400157 0.978738 2.240893
2013-01-02 1.867558 -0.977278 0.950088 -0.151357
2013-01-03 -0.103219 0.410599 0.144044 1.454274
인덱스 숫자를 사용하면 행을 슬라이스할 수 있습니다.
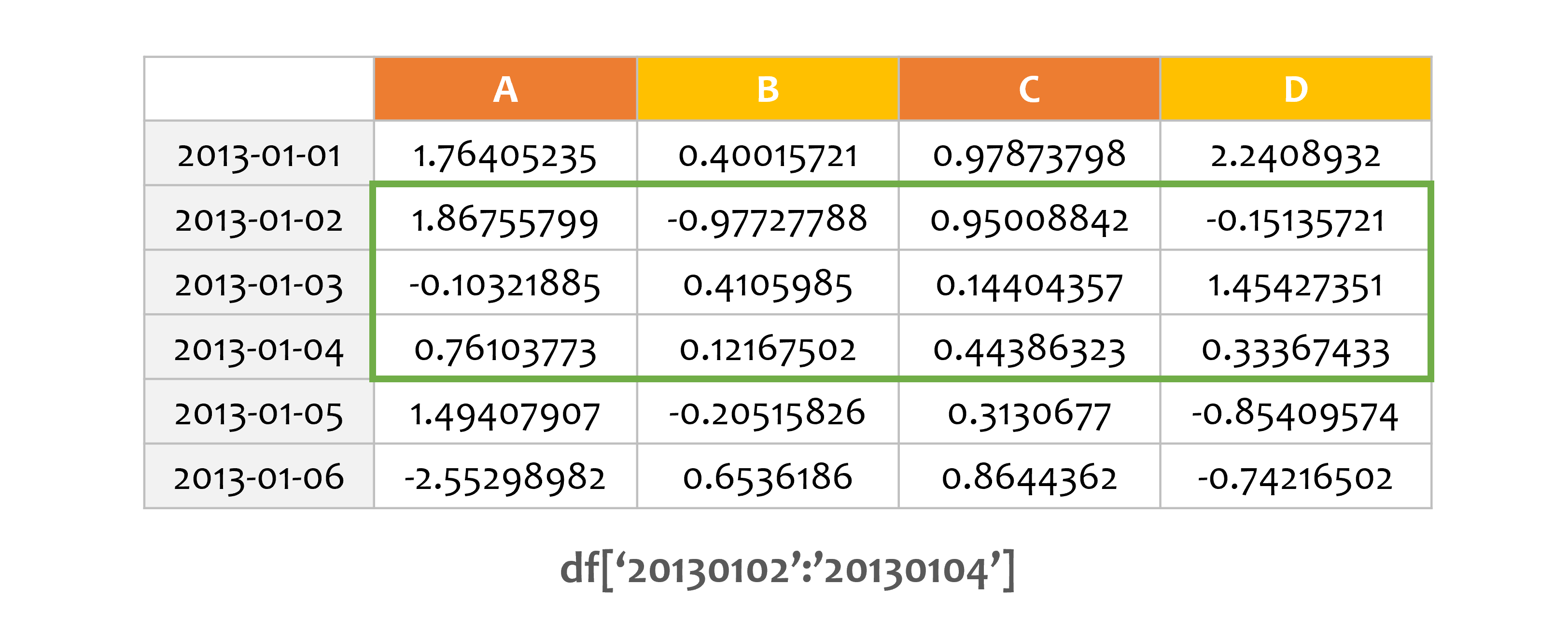
예제2¶
print(df['20130102':'20130104'])
A B C D
2013-01-02 1.867558 -0.977278 0.950088 -0.151357
2013-01-03 -0.103219 0.410599 0.144044 1.454274
2013-01-04 0.761038 0.121675 0.443863 0.333674
인덱스를 직접 사용해서 행을 선택할 수도 있습니다.
4) 레이블로 선택하기 (df.loc)¶
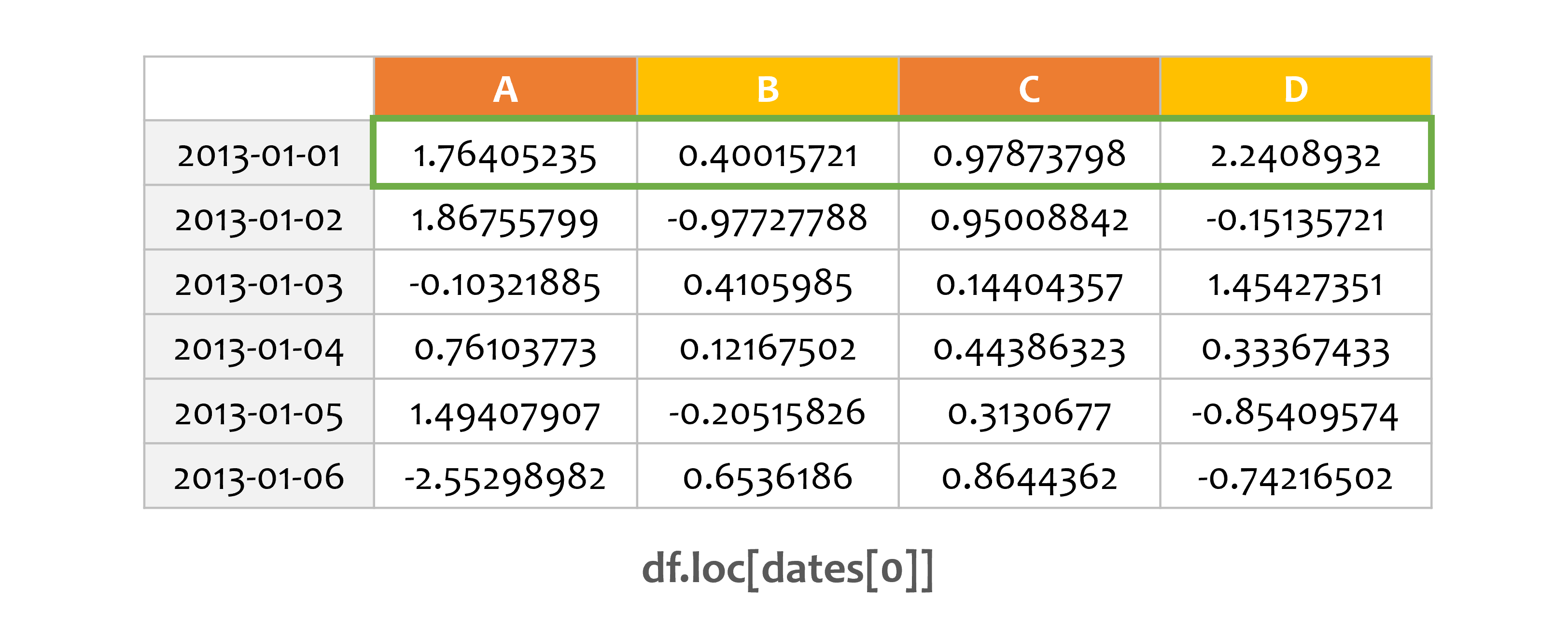
예제1¶
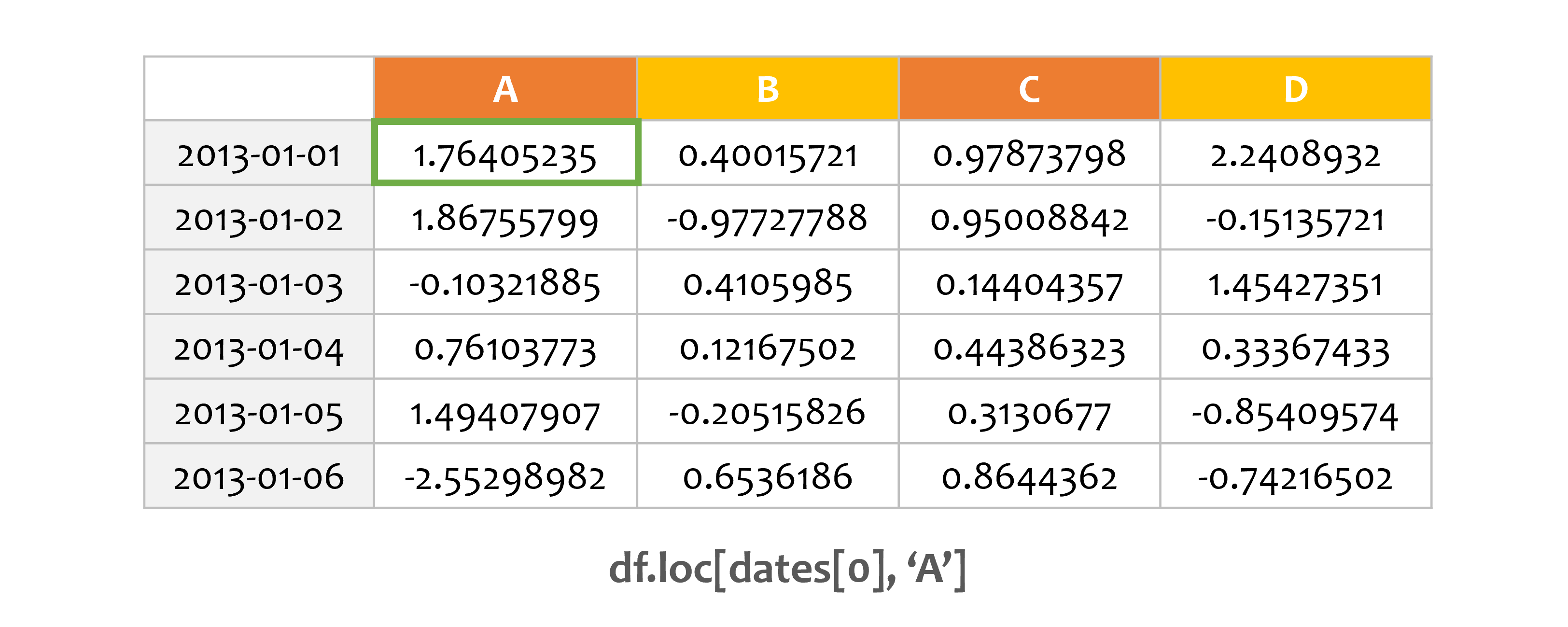
print(df.loc[dates[0]])
A 1.764052
B 0.400157
C 0.978738
D 2.240893
Name: 2013-01-01 00:00:00, dtype: float64
레이블을 이용해서 횡 방향 데이터를 얻습니다.
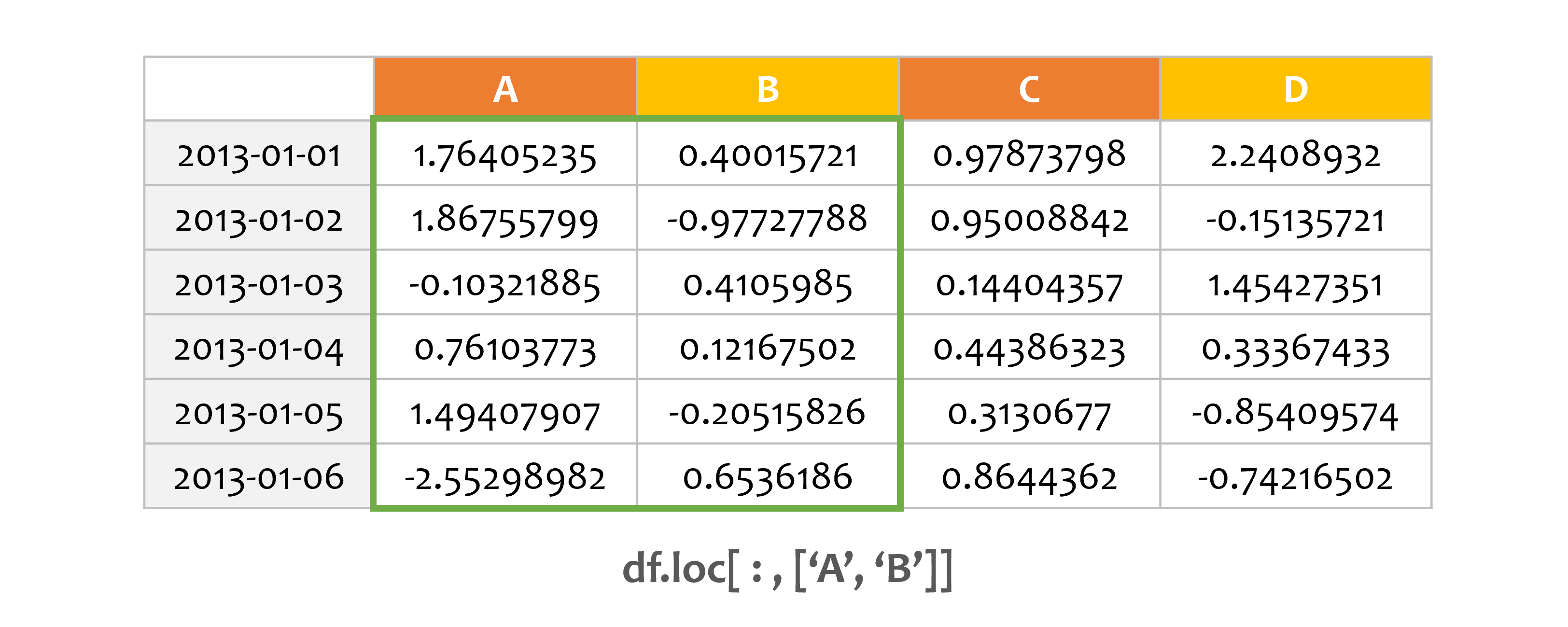
예제2¶
print(df.loc[:, ['A', 'B']])
A B
2013-01-01 1.764052 0.400157
2013-01-02 1.867558 -0.977278
2013-01-03 -0.103219 0.410599
2013-01-04 0.761038 0.121675
2013-01-05 1.494079 -0.205158
2013-01-06 -2.552990 0.653619
레이블을 이용해서 여러 축을 선택합니다.
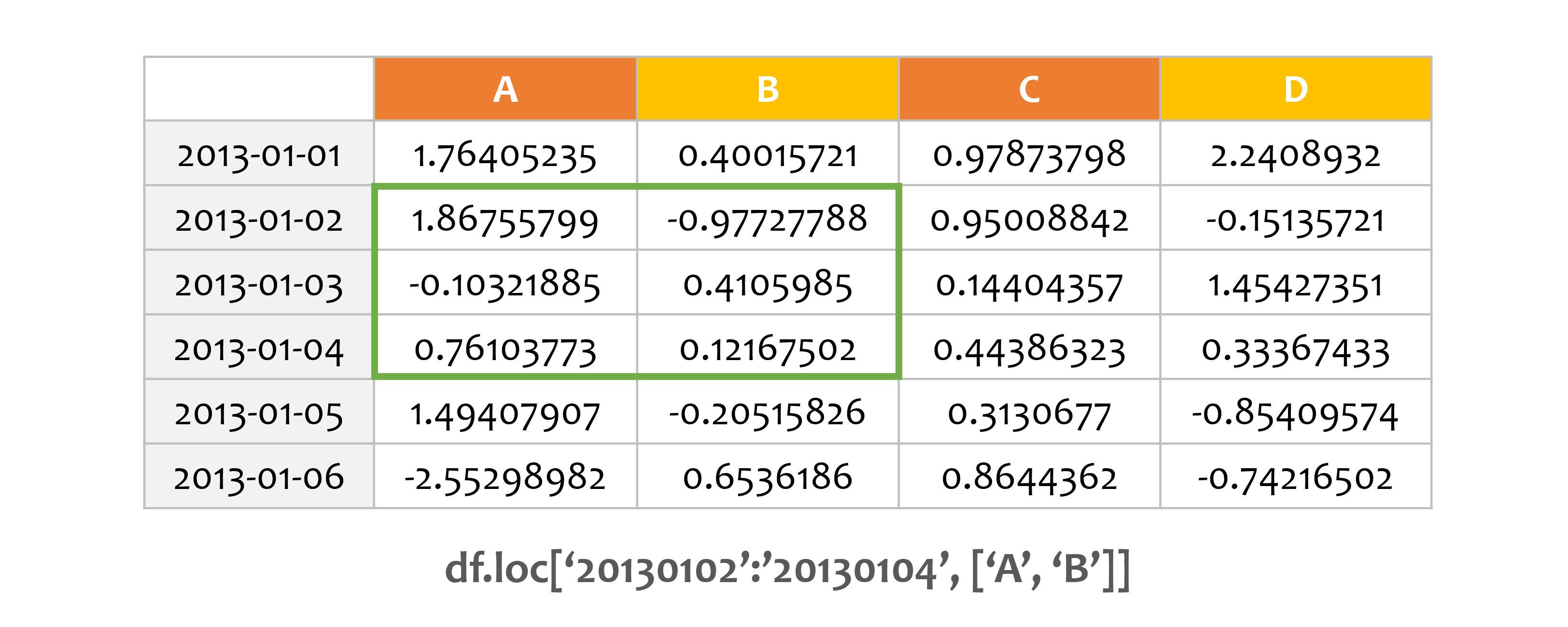
예제3¶
print(df.loc['20130102':'20130104', ['A', 'B']])
A B
2013-01-02 1.867558 -0.977278
2013-01-03 -0.103219 0.410599
2013-01-04 0.761038 0.121675
슬라이스를 사용하면, 양 끝이 모두 포함됩니다.
예제4¶
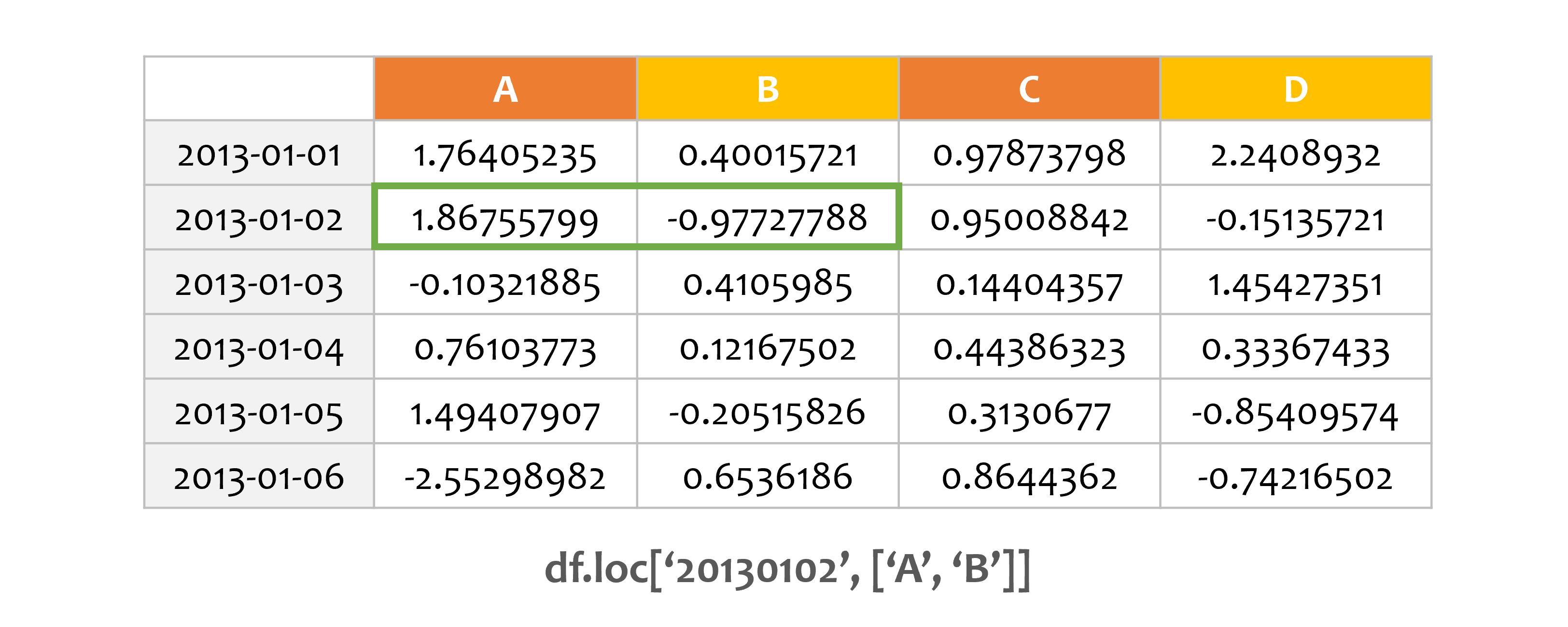
print(df.loc['20130102', ['A', 'B']])
A 1.867558B -0.977278
Name: 2013-01-02 00:00:00, dtype: float64
1차원으로 축소된 차원의 객체가 반환됩니다.
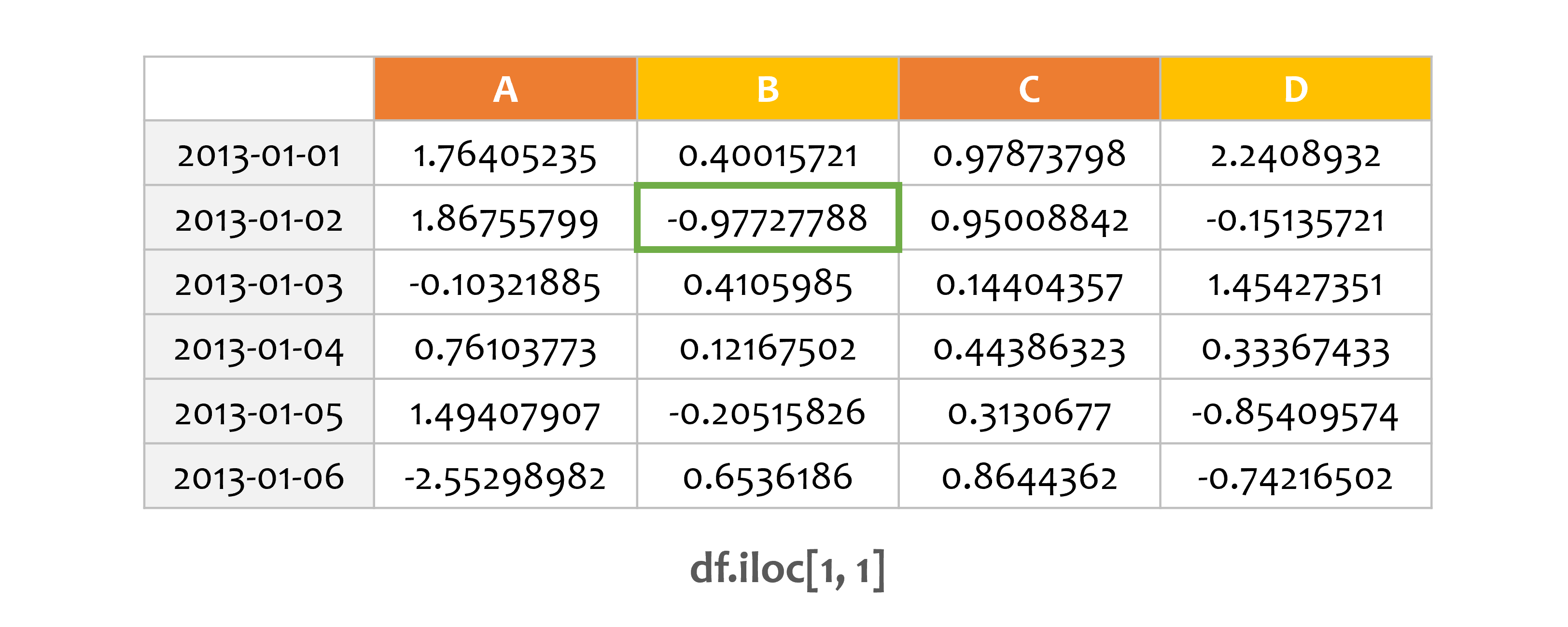
5) 위치로 선택하기 (df.iloc)¶
예제1¶
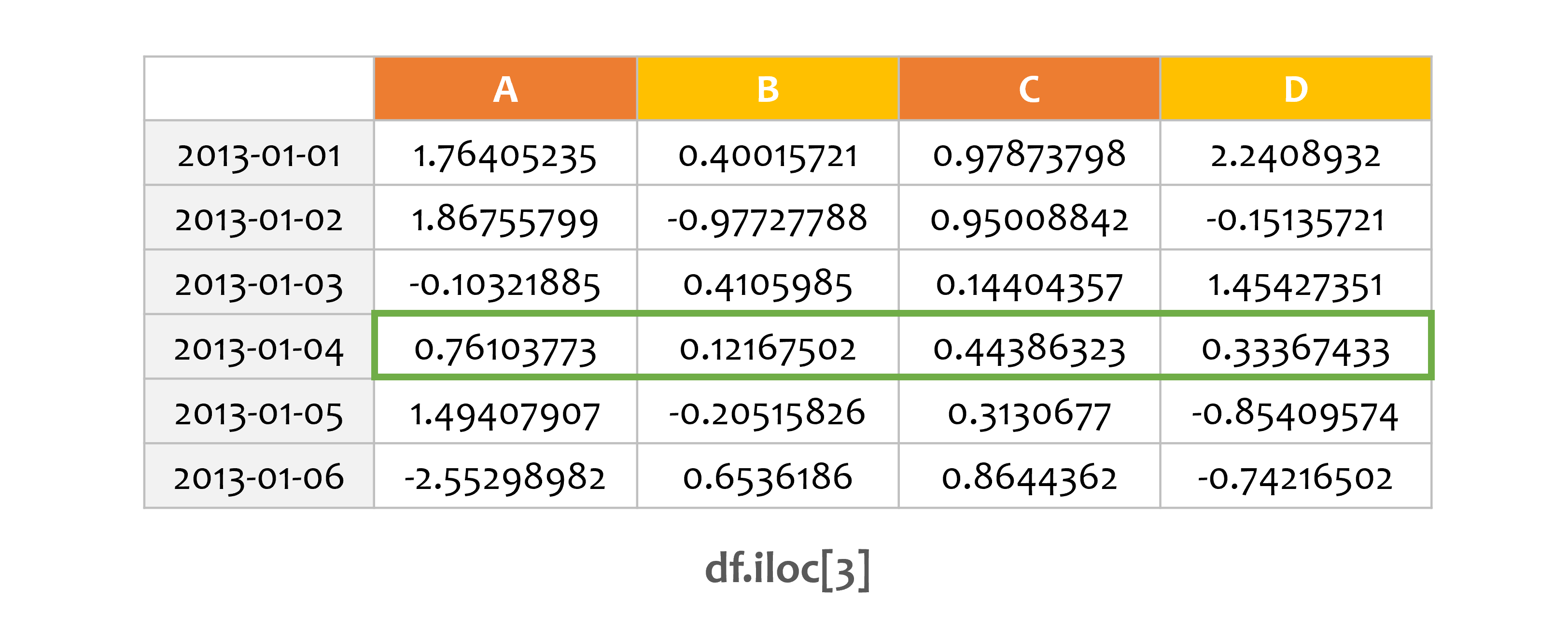
print(df.iloc[3])
A 0.761038
B 0.121675
C 0.443863
D 0.333674
Name: 2013-01-04 00:00:00, dtype: float64
iloc[n]과 같이 정수를 입력하면 해당 행을 선택합니다.
예제2¶
print(df.iloc[3:5, 0:2])
A B
2013-01-04 0.761038 0.121675
2013-01-05 1.494079 -0.205158
정수 슬라이스는 NumPy와 Python과 비슷하게 동작합니다.
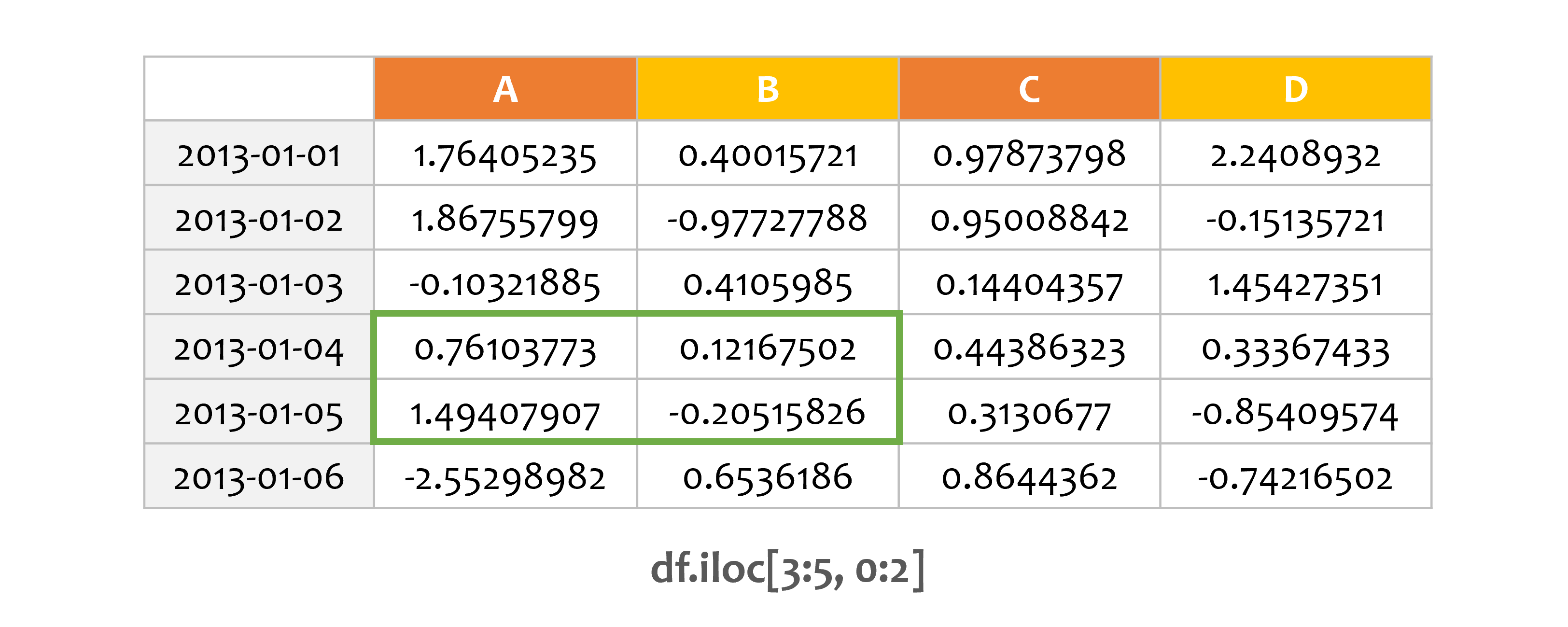
예제3¶
print(df.iloc[[1, 2, 4], [0, 2]])
A C
2013-01-02 1.867558 0.950088
2013-01-03 -0.103219 0.144044
2013-01-05 1.494079 0.313068
정수 위치의 리스트도 NumPy/Python과 비슷하게 동작합니다.
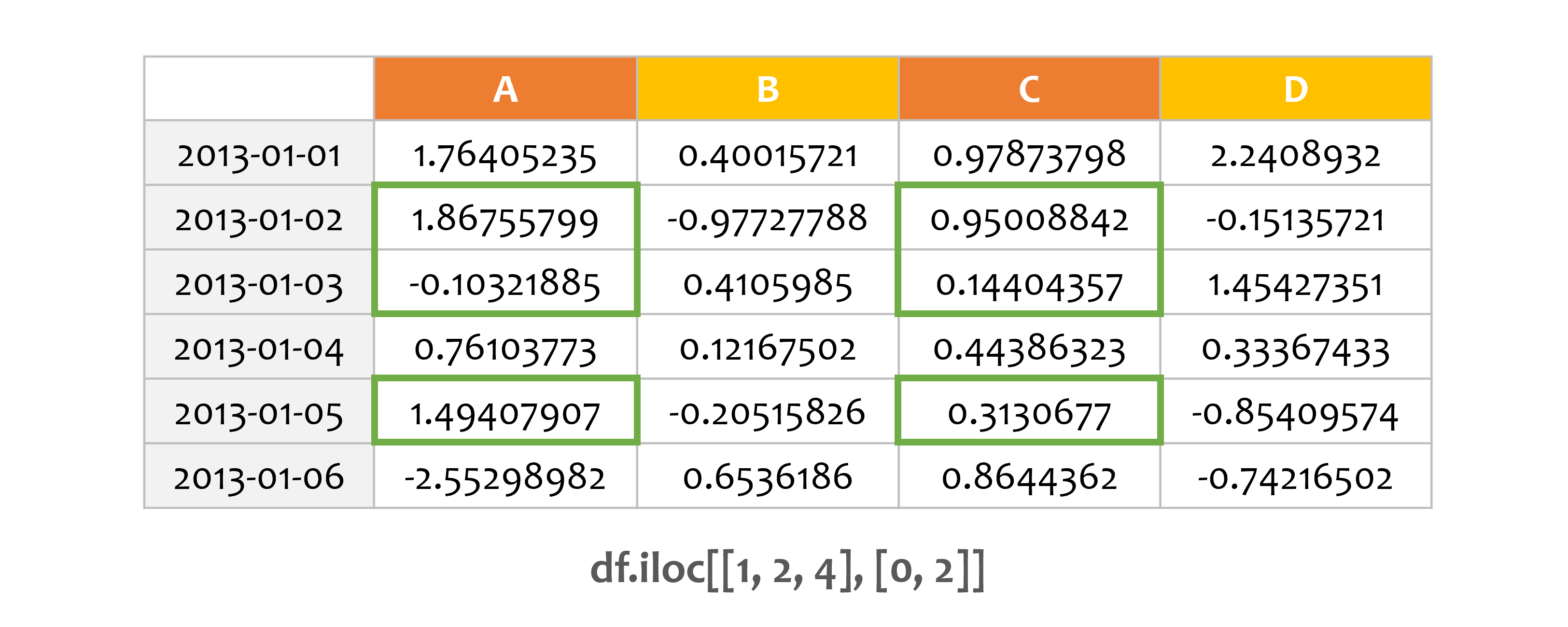
예제4¶
print(df.iloc[1:3, :])
A B C D
2013-01-02 1.867558 -0.977278 0.950088 -0.151357
2013-01-03 -0.103219 0.410599 0.144044 1.454274
iloc[1:3, : ]은 행을 명시적으로 슬라이스합니다.
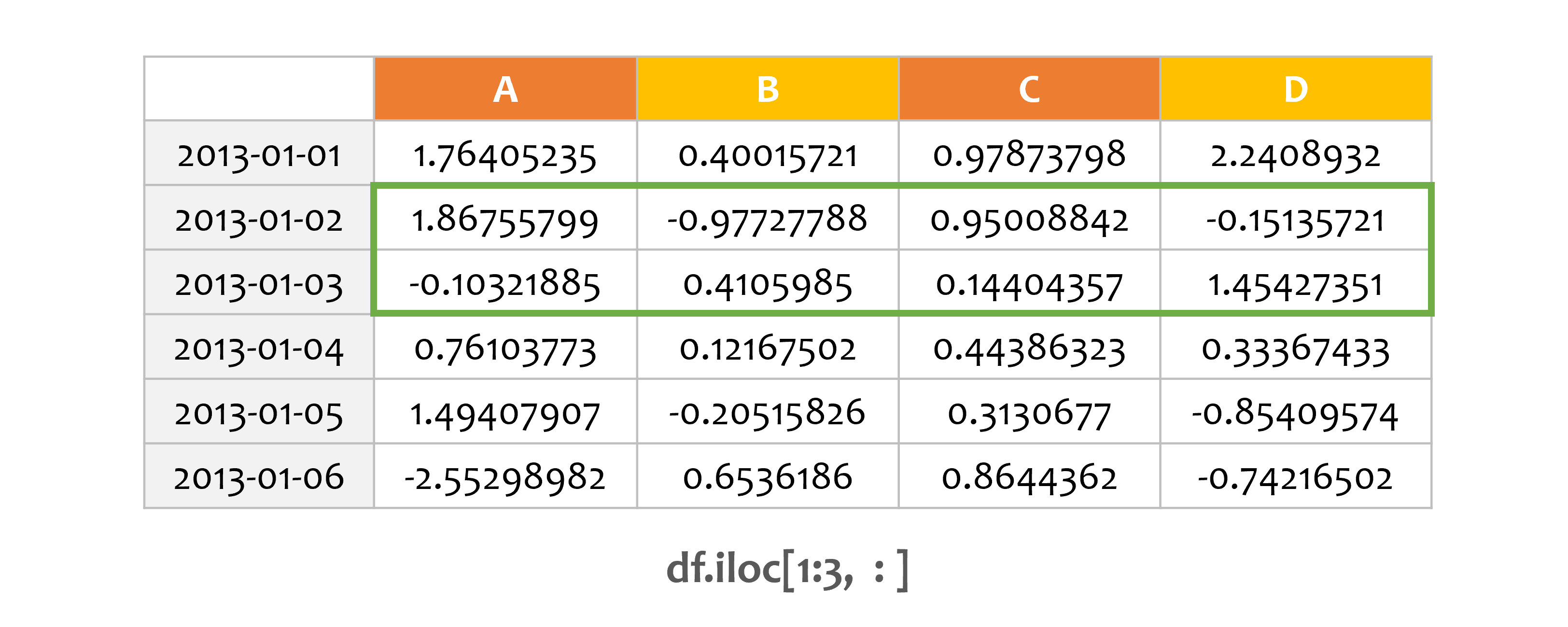
예제5¶
print(df.iloc[:, 1:3])
B C
2013-01-01 0.400157 0.978738
2013-01-02 -0.977278 0.950088
2013-01-03 0.410599 0.144044
2013-01-04 0.121675 0.443863
2013-01-05 -0.205158 0.313068
2013-01-06 0.653619 0.864436
iloc[ : , 1:3]은 열을 명시적으로 슬라이스합니다.
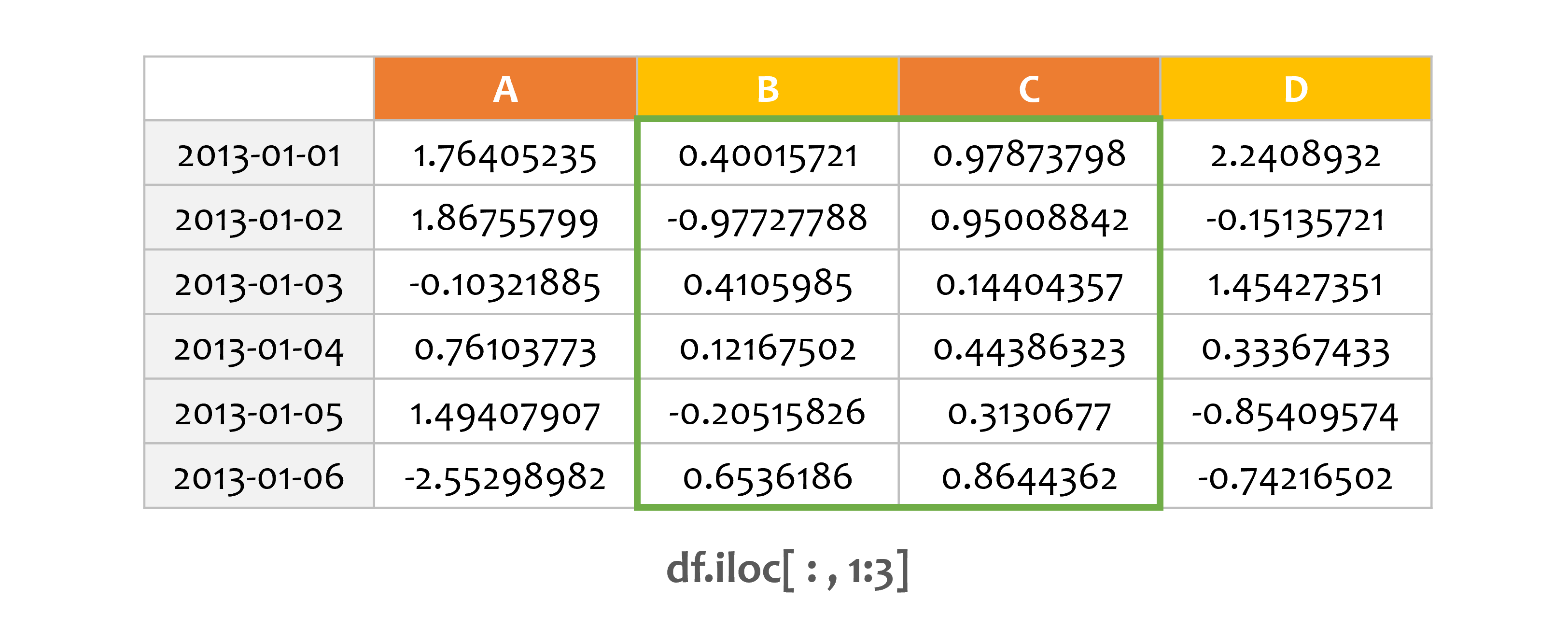
6) 불 인덱싱¶
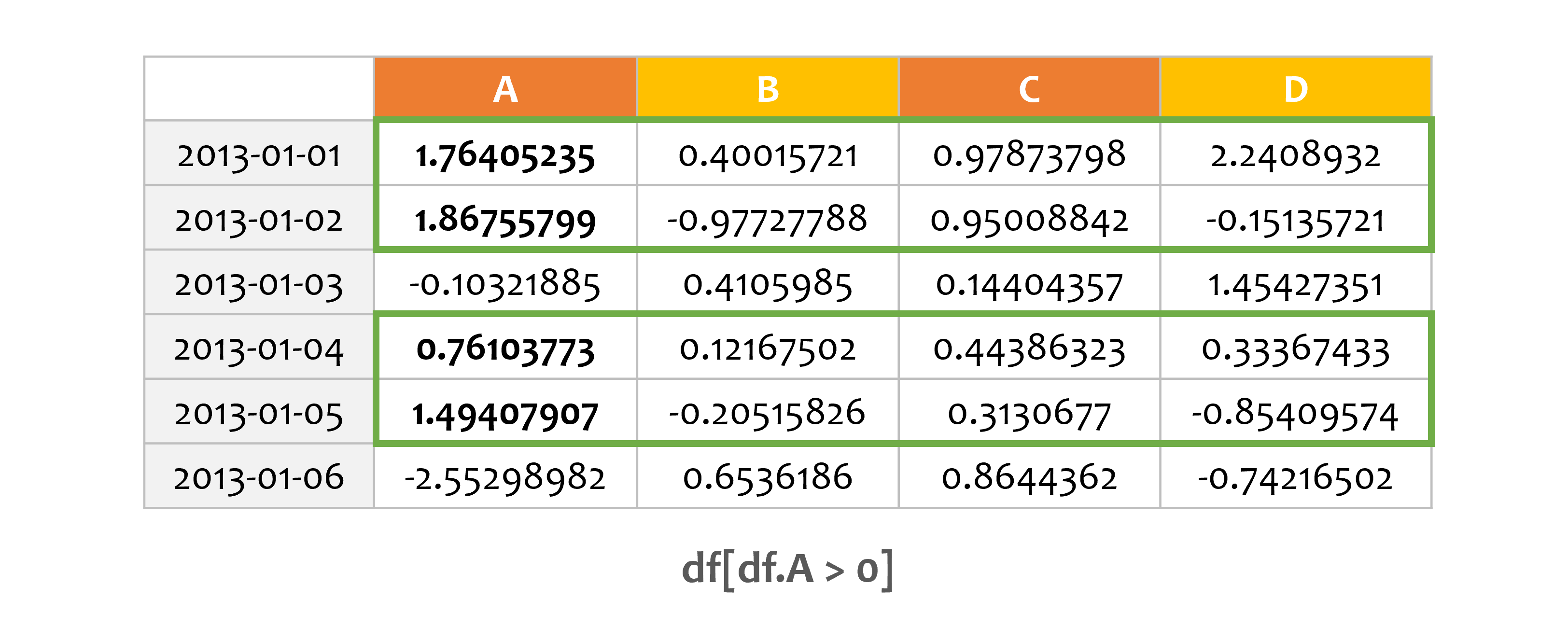
예제1¶
print(df[df.A > 0])
A B C D
2013-01-01 1.764052 0.400157 0.978738 2.240893
2013-01-02 1.867558 -0.977278 0.950088 -0.151357
2013-01-04 0.761038 0.121675 0.443863 0.333674
2013-01-05 1.494079 -0.205158 0.313068 -0.854096
하나의 열의 값을 기준으로 데이터를 선택할 수 있습니다.
df[df.A > 0]은 df로부터 A열이 0보다 큰 데이터를 보여줍니다.
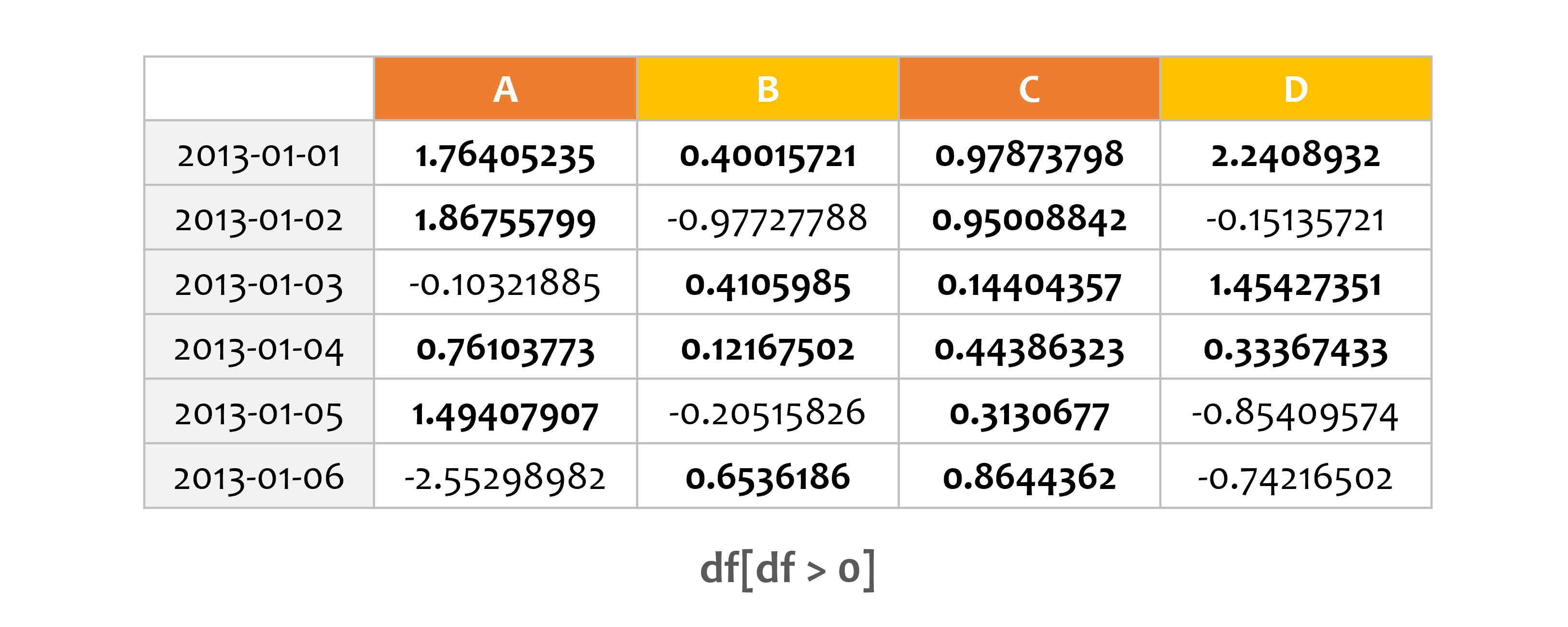
예제2¶
print(df[df > 0])
A B C D
2013-01-01 1.764052 0.400157 0.978738 2.240893
2013-01-02 1.867558 NaN 0.950088 NaN
2013-01-03 NaN 0.410599 0.144044 1.454274
2013-01-04 0.761038 0.121675 0.443863 0.333674
2013-01-05 1.494079 NaN 0.313068 NaN
2013-01-06 NaN 0.653619 0.864436 NaN
조건식이 성립하는 값들을 DataFrame으로부터 선택합니다.
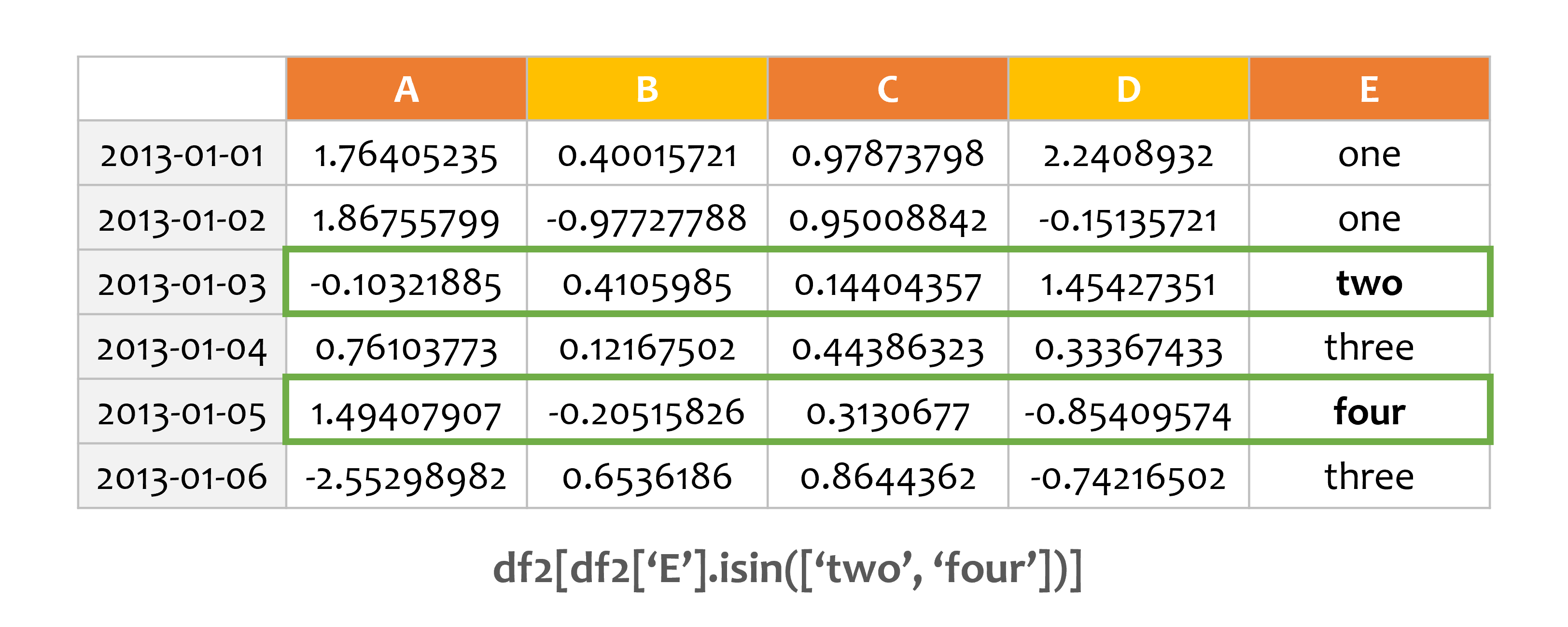
예제3¶
df2 = df.copy()
df2['E'] = ['one', 'one', 'two', 'three', 'four', 'three']
print(df2)
print(df2[df2['E'].isin(['two', 'four'])])
A B C D E
2013-01-01 1.764052 0.400157 0.978738 2.240893 one
2013-01-02 1.867558 -0.977278 0.950088 -0.151357 one
2013-01-03 -0.103219 0.410599 0.144044 1.454274 two
2013-01-04 0.761038 0.121675 0.443863 0.333674 three
2013-01-05 1.494079 -0.205158 0.313068 -0.854096 four
2013-01-06 -2.552990 0.653619 0.864436 -0.742165 three
A B C D E
2013-01-03 -0.103219 0.410599 0.144044 1.454274 two
2013-01-05 1.494079 -0.205158 0.313068 -0.854096 four
isin() 메서드를 이용해서 E열의 값이 ‘two’와 ‘four’를 포함하는 경우를 필터링합니다.
7) 데이터 설정하기¶
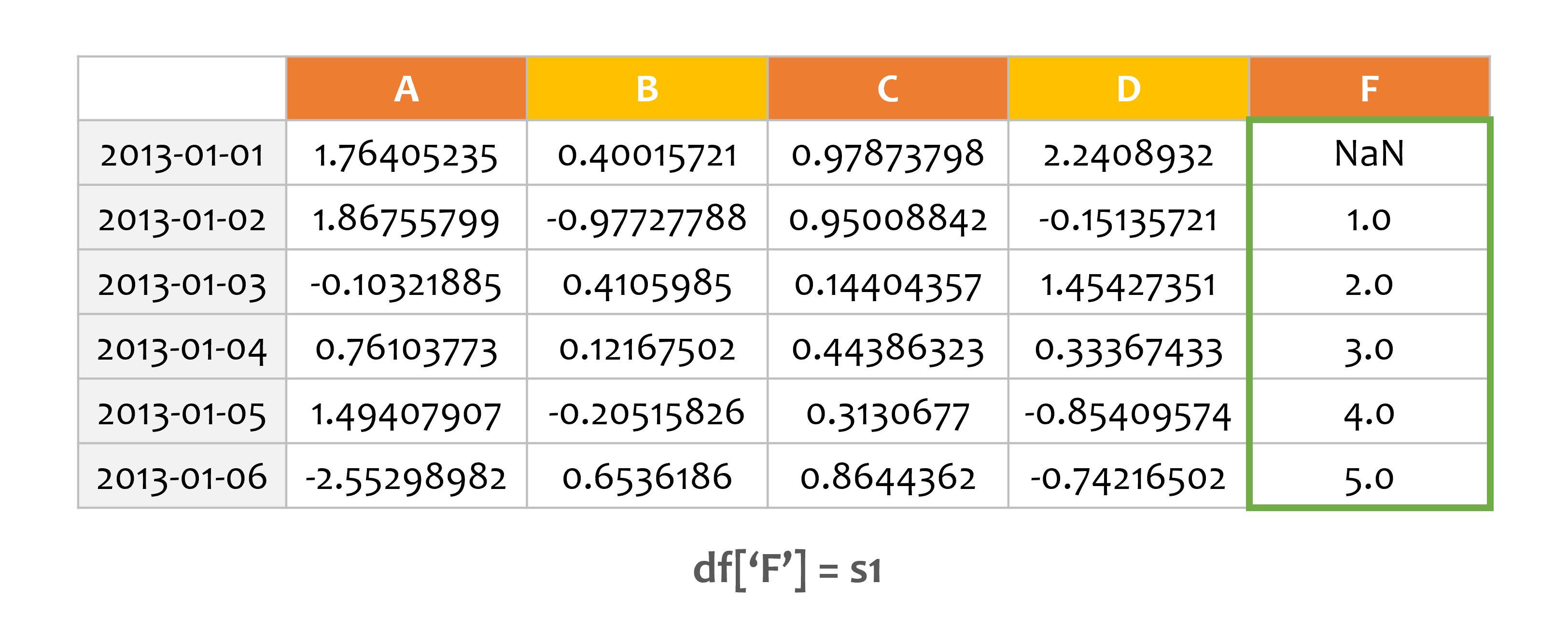
예제1¶
s1 = pd.Series([1, 2, 3, 4, 5, 6], index=pd.date_range('20130102', periods=6))
print(s1)
df['F'] = s1
print(df)
2013-01-02 1
2013-01-03 2
2013-01-04 3
2013-01-05 4
2013-01-06 5
2013-01-07 6
Freq: D, dtype: int64
A B C D F
2013-01-01 0.000000 0.400157 0.978738 2.240893 NaN
2013-01-02 1.867558 -0.977278 0.950088 -0.151357 1.0
2013-01-03 -0.103219 0.410599 0.144044 1.454274 2.0
2013-01-04 0.761038 0.121675 0.443863 0.333674 3.0
2013-01-05 1.494079 -0.205158 0.313068 -0.854096 4.0
2013-01-06 -2.552990 0.653619 0.864436 -0.742165 5.0
새로운 열을 설정하면, 인덱스에 따라 데이터가 자동 정렬됩니다.
새로운 Series를 하나 만들어서 DataFrame의 ‘F’열로 지정했습니다.
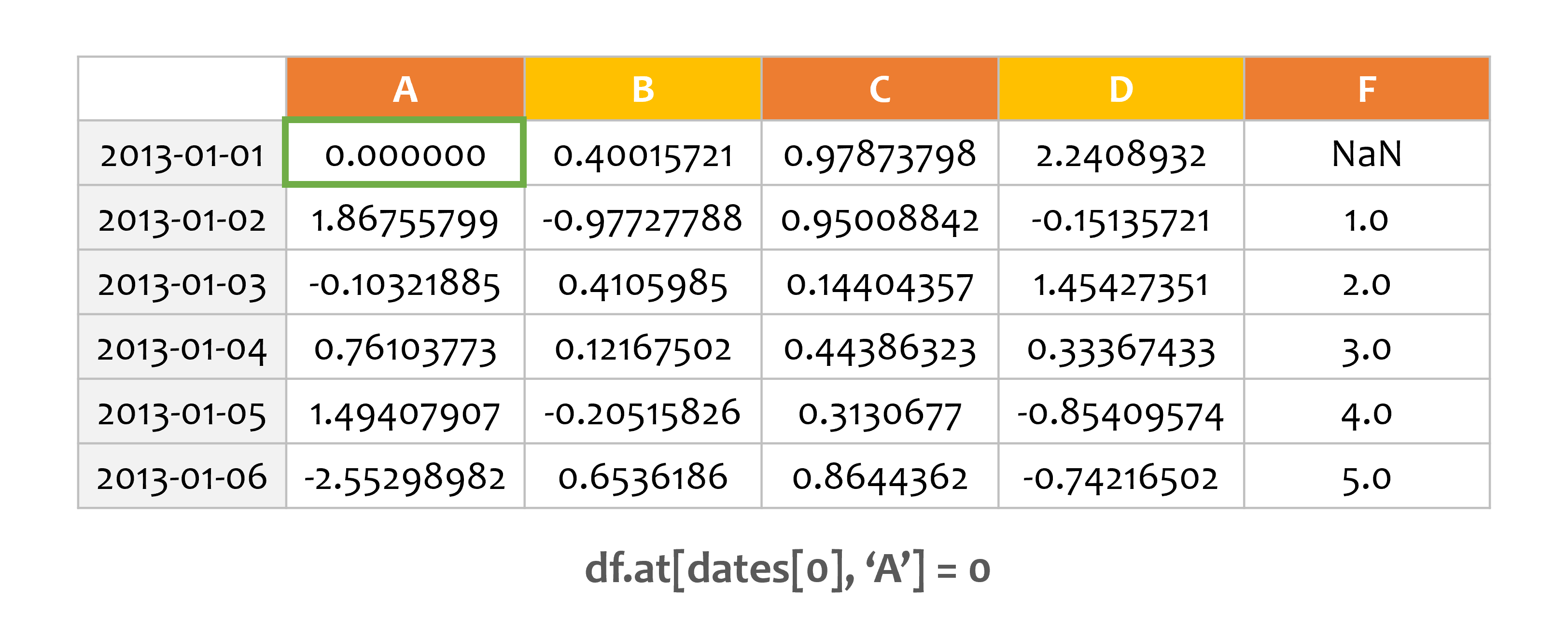
예제2¶
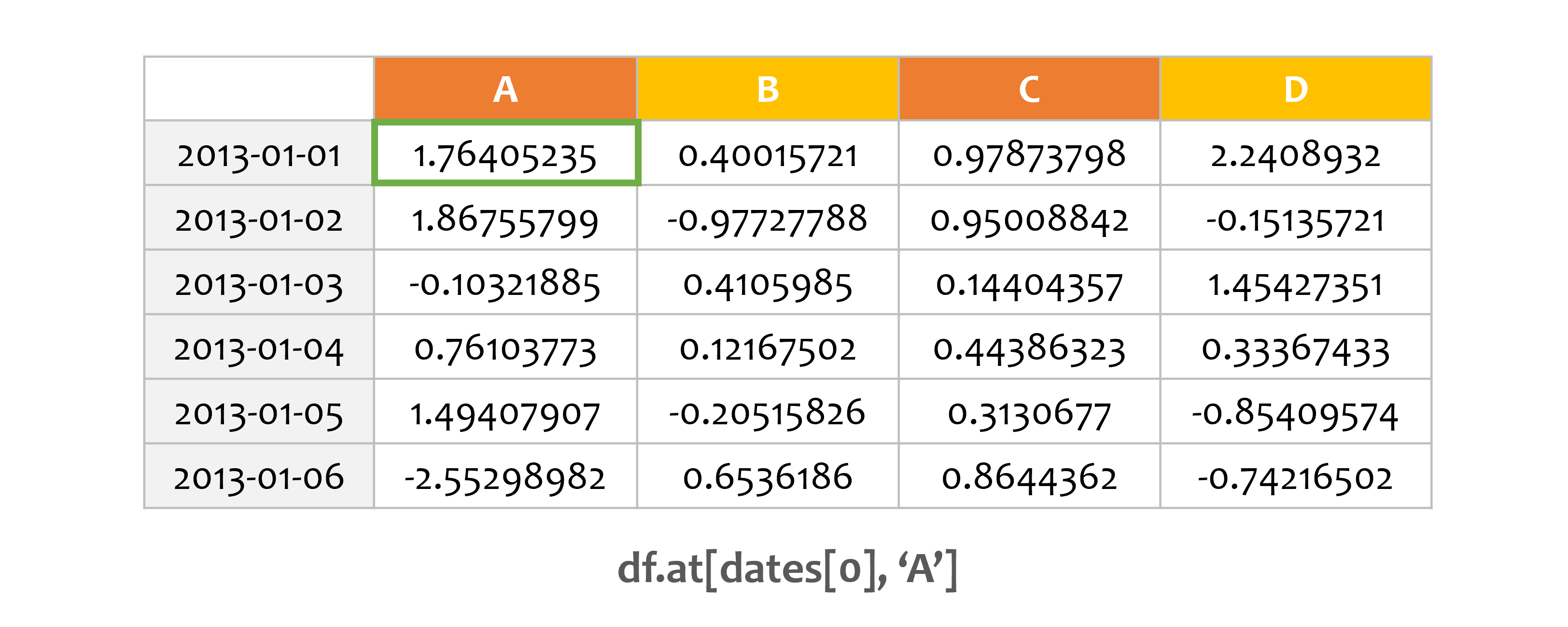
df.at[dates[0], 'A'] = 0
print(df)
A B C D F
2013-01-01 0.000000 0.400157 0.978738 2.240893 NaN
2013-01-02 1.867558 -0.977278 0.950088 -0.151357 1.0
2013-01-03 -0.103219 0.410599 0.144044 1.454274 2.0
2013-01-04 0.761038 0.121675 0.443863 0.333674 3.0
2013-01-05 1.494079 -0.205158 0.313068 -0.854096 4.0
2013-01-06 -2.552990 0.653619 0.864436 -0.742165 5.0
at과 레이블을 사용해서 값을 설정할 수 있습니다.
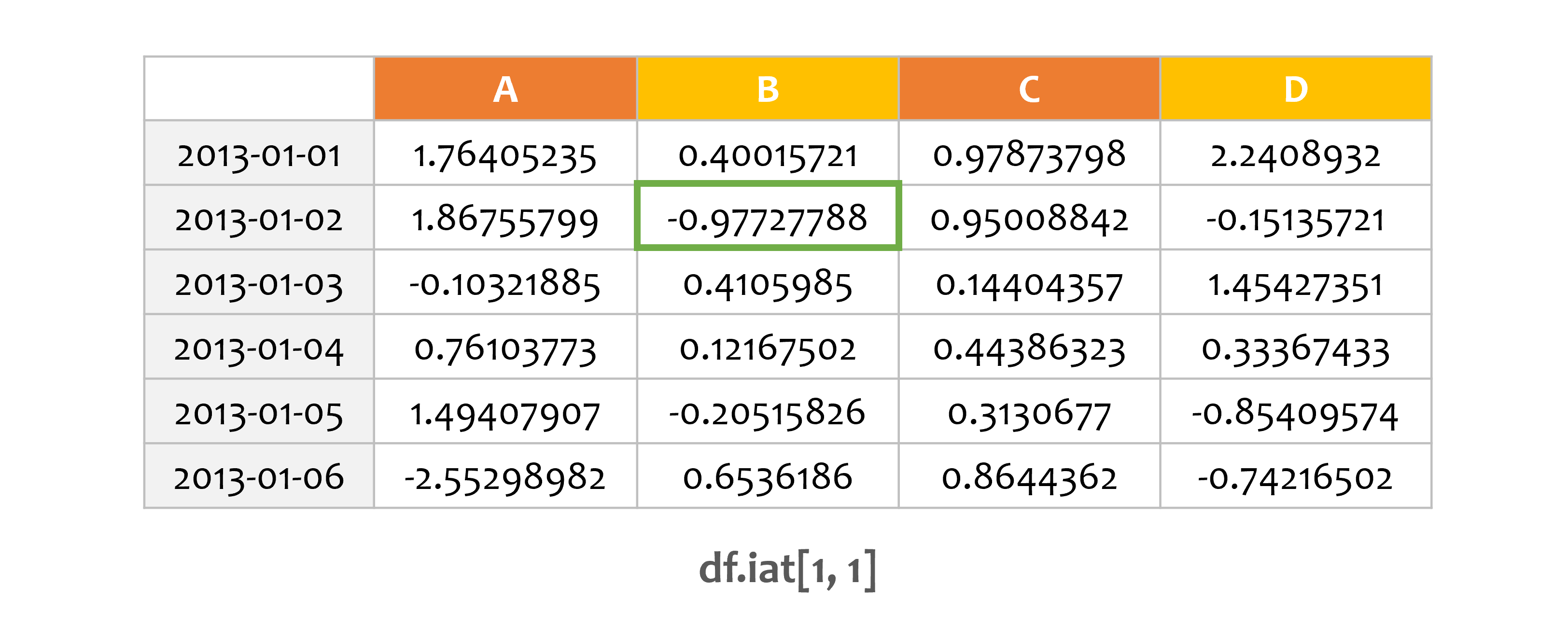
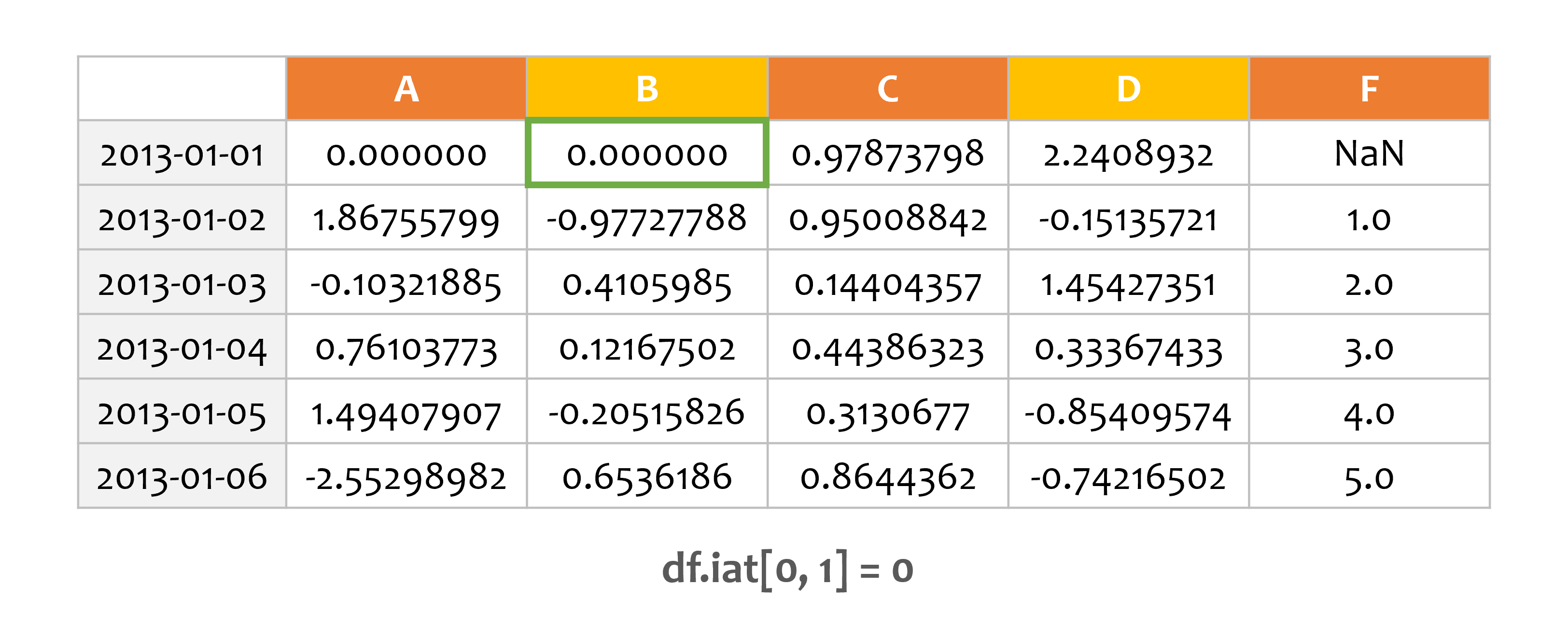
예제3¶
df.iat[0, 1] = 0
print(df)
A B C D F
2013-01-01 0.000000 0.000000 0.978738 2.240893 NaN
2013-01-02 1.867558 -0.977278 0.950088 -0.151357 1.0
2013-01-03 -0.103219 0.410599 0.144044 1.454274 2.0
2013-01-04 0.761038 0.121675 0.443863 0.333674 3.0
2013-01-05 1.494079 -0.205158 0.313068 -0.854096 4.0
2013-01-06 -2.552990 0.653619 0.864436 -0.742165 5.0
iat과 위치 인덱스를 이용해서 값을 설정할 수도 있습니다.
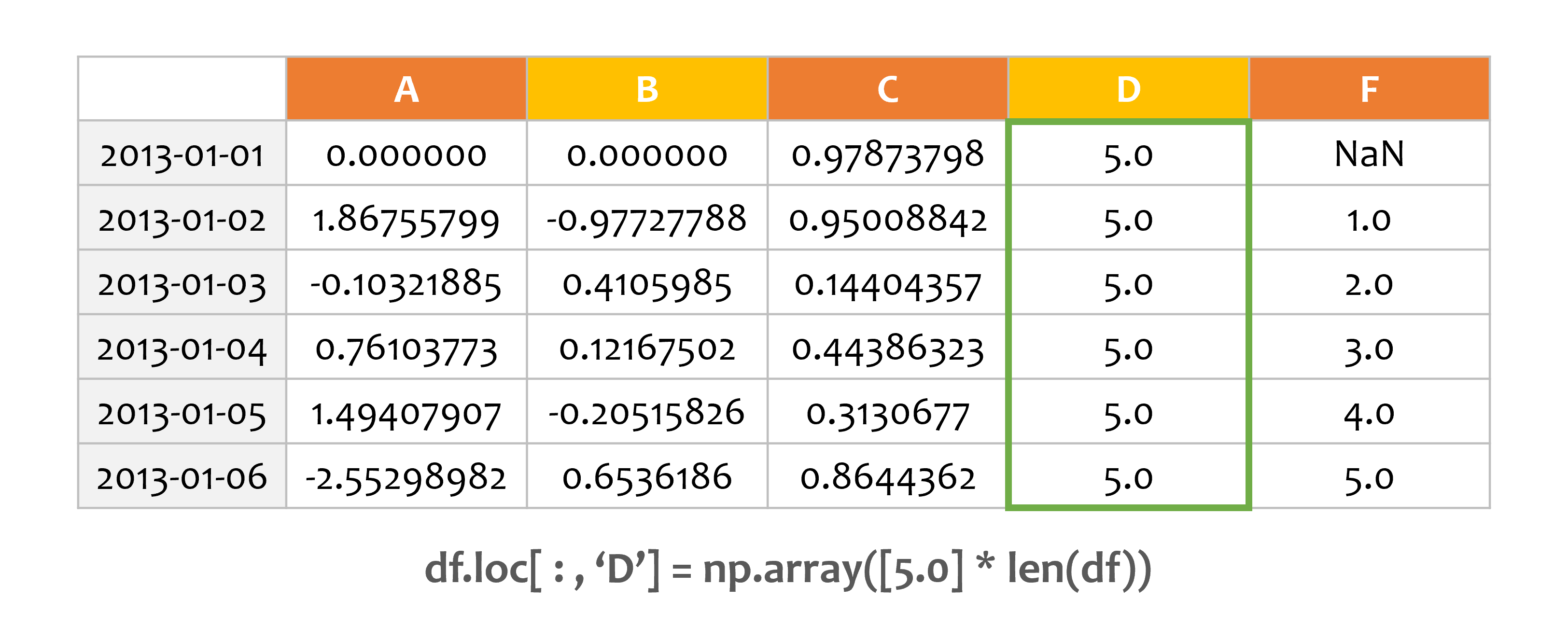
예제4¶
df.loc[:, 'D'] = np.array([5] * len(df))
print(df)
A B C D F
2013-01-01 0.000000 0.000000 0.978738 5.0 NaN
2013-01-02 1.867558 -0.977278 0.950088 5.0 1.0
2013-01-03 -0.103219 0.410599 0.144044 5.0 2.0
2013-01-04 0.761038 0.121675 0.443863 5.0 3.0
2013-01-05 1.494079 -0.205158 0.313068 5.0 4.0
2013-01-06 -2.552990 0.653619 0.864436 5.0 5.0
loc을 사용해서 NumPy 어레이를 할당함으로써 값을 설정했습니다.
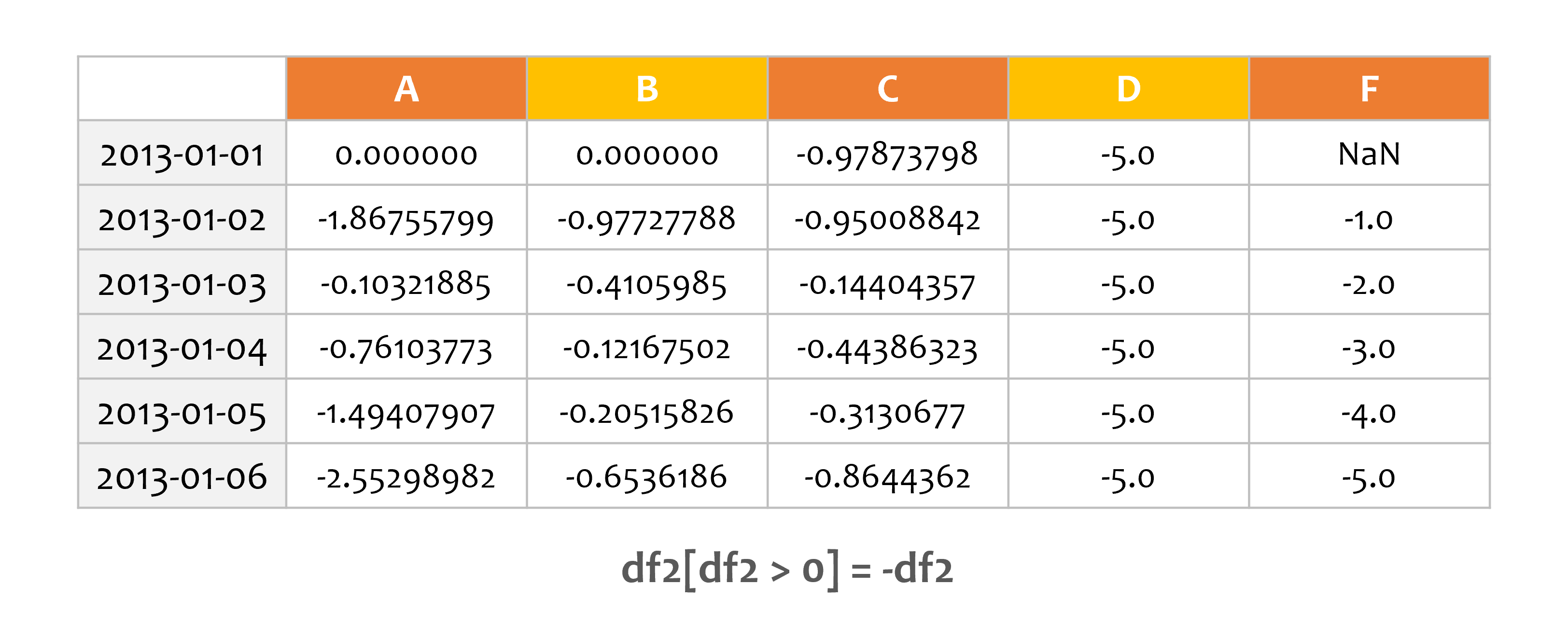
예제5¶
df2 = df.copy()
df2[df2 > 0] = -df2
print(df2)
A B C D F
2013-01-01 0.000000 0.000000 -0.978738 -5.0 NaN
2013-01-02 -1.867558 -0.977278 -0.950088 -5.0 -1.0
2013-01-03 -0.103219 -0.410599 -0.144044 -5.0 -2.0
2013-01-04 -0.761038 -0.121675 -0.443863 -5.0 -3.0
2013-01-05 -1.494079 -0.205158 -0.313068 -5.0 -4.0
2013-01-06 -2.552990 -0.653619 -0.864436 -5.0 -5.0
조건식을 이용해서 값을 설정할 수 있습니다.
DataFrame (df2)를 하나 만들고 0보다 큰 값들의 부호를 반대로 했습니다.