Contents
- PyQt5 Tutorial - 파이썬으로 만드는 나만의 GUI 프로그램
- 1. PyQt5 소개 (Introduction)
- 2. PyQt5 설치 (Installation)
- 3. PyQt5 기초 (Basics)
- 4. PyQt5 레이아웃 (Layout)
- 5. PyQt5 위젯 (Widget)
- QPushButton
- QLabel
- QCheckBox
- QRadioButton
- QComboBox
- QLineEdit
- QLineEdit (Advanced)
- QProgressBar
- QSlider & QDial
- QSplitter
- QGroupBox
- QTabWidget
- QTabWidget (Advanced)
- QPixmap
- QCalendarWidget
- QSpinBox
- QDoubleSpinBox
- QDateEdit
- QTimeEdit
- QDateTimeEdit
- QTextBrowser
- QTextBrowser (Advanced)
- QTextEdit
- QTableWidget
- QTableWidget (Advanced)
- 6. PyQt5 다이얼로그 (Dialog)
- 7. PyQt5 시그널과 슬롯 (Signal&Slot)
- 8. PyQt5 그림 그리기 (Updated)
- 9. PyQt5 실행파일 만들기 (PyInstaller)
- 10. PyQt5 프로그램 예제 (Updated)
- ▷ PDF ebook
Tutorials
- Python Tutorial
- NumPy Tutorial
- Matplotlib Tutorial
- PyQt5 Tutorial
- BeautifulSoup Tutorial
- xlrd/xlwt Tutorial
- Pillow Tutorial
- Googletrans Tutorial
- PyWin32 Tutorial
- PyAutoGUI Tutorial
- Pyperclip Tutorial
- TensorFlow Tutorial
- Tips and Examples
QTextBrowser (Advanced)¶
웹 크롤링을 이용해서 BBC 뉴스의 검색 결과 헤드라인을 가져와 보겠습니다.
크롤링에 대해 익숙하지 않다면, 아래의 링크를 먼저 확인하세요.
예제¶
## Ex 5-19-1. QTextBrowser (Advanced).
import sys
from PyQt5.QtWidgets import *
import requests
from bs4 import BeautifulSoup
class MyApp(QWidget):
def __init__(self):
super().__init__()
self.initUI()
def initUI(self):
self.le = QLineEdit()
self.le.setPlaceholderText('Enter your search word')
self.le.returnPressed.connect(self.crawl_news)
self.btn = QPushButton('Search')
self.btn.clicked.connect(self.crawl_news)
self.lbl = QLabel('')
self.tb = QTextBrowser()
self.tb.setAcceptRichText(True)
self.tb.setOpenExternalLinks(True)
grid = QGridLayout()
grid.addWidget(self.le, 0, 0, 1, 3)
grid.addWidget(self.btn, 0, 3, 1, 1)
grid.addWidget(self.lbl, 1, 0, 1, 4)
grid.addWidget(self.tb, 2, 0, 1, 4)
self.setLayout(grid)
self.setWindowTitle('Web Crawler')
self.setGeometry(100, 100, 700, 450)
self.show()
def crawl_news(self):
search_word = self.le.text()
if search_word:
self.lbl.setText('BBC Search Results for "' + search_word + '"')
self.tb.clear()
url_search = 'https://www.bbc.co.uk/search?q='
url = url_search + search_word
r = requests.get(url)
html = r.content
soup = BeautifulSoup(html, 'html.parser')
titles_html = soup.select('.search-results > li > article > div > h1 > a')
for i in range(len(titles_html)):
title = titles_html[i].text
link = titles_html[i].get('href')
self.tb.append(str(i + 1) + '. ' + title + ' (' + '<a href="' + link + '">Link</a>' + ')')
if __name__ == '__main__':
app = QApplication(sys.argv)
ex = MyApp()
sys.exit(app.exec_())
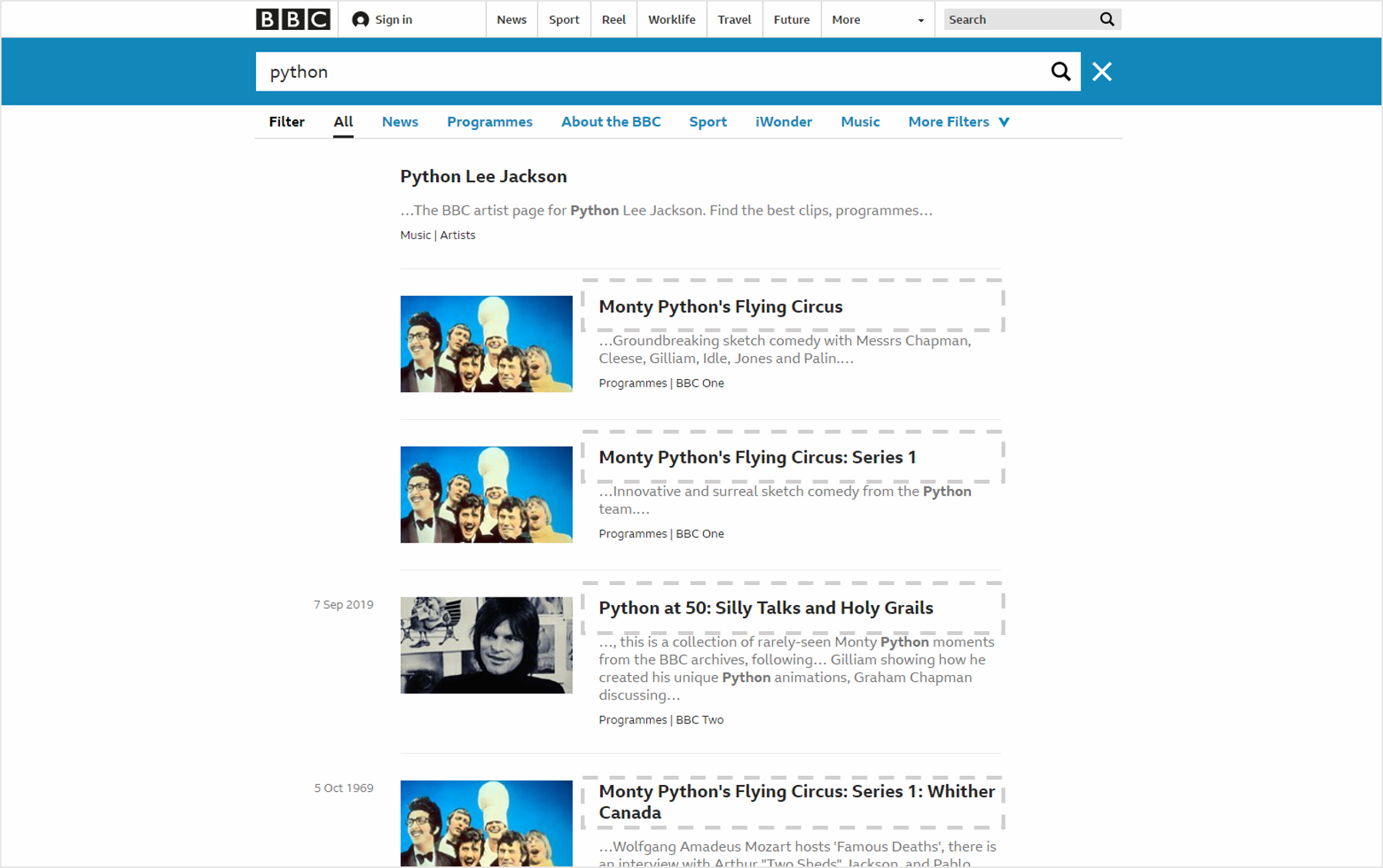
검색어를 입력하고 버튼을 클릭하면, BBC 뉴스 검색 결과와 링크가 텍스트 브라우저에 출력됩니다.
설명¶
import sys
from PyQt5.QtWidgets import *
import requests
from bs4 import BeautifulSoup
PyQt5와 관련된 모듈 외에, 크롤링에 필요한 requests, BeautifulSoup 라이브러리도 불러옵니다.
self.le = QLineEdit()
self.le.setPlaceholderText('Enter your search word')
self.le.returnPressed.connect(self.crawl_news)
QLineEdit()을 이용해서 날짜를 입력할 줄편집기를 하나 만들어 줍니다.
setPlaceholderText를 이용해서, 줄편집기에 ‘Enter your search word’가 표시되어 있도록 설정해 줍니다.
returnPressed는 Enter 키가 눌렸을 때 발생하는 시그널입니다. crawl_news 메서드에 연결해 줍니다.
self.btn = QPushButton('Search')
self.btn.clicked.connect(self.crawl_news)
‘Search’ 버튼을 만들어 줍니다. 버튼을 클릭해도 crawl_news 메서드가 호출됩니다.
self.tb = QTextBrowser()
self.tb.setAcceptRichText(True)
self.tb.setOpenExternalLinks(True)
QTextBrowser() 클래스를 이용해서 텍스트 브라우저를 만들어 줍니다.
서식 있는 텍스트를 허용해주는 setAcceptRichText는 디폴트로 True로 설정되어 있기 때문에 굳이 작성하지 않아도 되는 부분입니다.
setOpenExternalLinks()를 이용해서 외부 링크를 허용해줍니다.
grid = QGridLayout()
grid.addWidget(self.le, 0, 0, 1, 3)
grid.addWidget(self.btn, 0, 3, 1, 1)
grid.addWidget(self.lbl, 1, 0, 1, 4)
grid.addWidget(self.tb, 2, 0, 1, 4)
self.setLayout(grid)
그리드 레이아웃을 이용해서, 줄 편집기 (self.le), ‘Search’ 버튼 (self.btn), 라벨 (self.lbl), 텍스트 브라우저 (self.tb)를 각각 적절한 위치에 배치합니다.
addWidget의 첫번째 인수는 추가할 위젯, 두세번째 인수는 행과 열의 위치, 세네번째 인수는 행과 열이 차지하는 칸을 입력해 줍니다.
def crawl_news(self):
search_word = self.le.text()
if search_word:
self.lbl.setText('BBC Search Results for "' + search_word + '"')
self.tb.clear()
줄 편집기에 입력된 텍스트를 search_word에 할당합니다. 입력된 검색어가 있다면, 라벨에 ‘BBC Search Results for “search_word“‘가 표시되도록 합니다.
self.tb.clear()를 이용해서 이전에 텍스트 브라우저에 표시된 텍스트를 없애줍니다.
url_search = 'https://www.bbc.co.uk/search?q='
url = url_search + search_word
r = requests.get(url)
html = r.content
soup = BeautifulSoup(html, 'html.parser')
titles_html = soup.select('.search-results > li > article > div > h1 > a')
해당 주소에 접속해서 뉴스 검색 결과의 제목에 해당하는 텍스트를 선택합니다.
for i in range(len(titles_html)):
title = titles_html[i].text
link = titles_html[i].get('href')
self.tb.append(str(i+1) + '. ' + title + ' (' + '<a href="' + link + '">Link</a>' + ')')
titles_html[i].text는 a 태그 안의 텍스트이고, titles_html[i].get(‘href’)는 a 태그의 링크 주소입니다.
텍스트 브라우저에 뉴스의 제목과 링크를 추가해 줍니다.