Contents
- TensorFlow - 구글 머신러닝 플랫폼
- 1. 텐서 기초 살펴보기
- 2. 간단한 신경망 만들기
- 3. 손실 함수 살펴보기
- 4. 옵티마이저 사용하기
- 5. AND 로직 연산 학습하기
- 6. 뉴런층의 속성 확인하기
- 7. 뉴런층의 출력 확인하기
- 8. MNIST 손글씨 이미지 분류하기
- 9. Fashion MNIST 이미지 분류하기
- 10. 합성곱 신경망 사용하기
- 11. 말과 사람 이미지 분류하기
- 12. 고양이와 개 이미지 분류하기
- 13. 이미지 어그멘테이션의 효과
- 14. 전이 학습 활용하기
- 15. 다중 클래스 분류 문제
- 16. 시냅스 가중치 얻기
- 17. 시냅스 가중치 적용하기
- 18. 모델 시각화하기
- 19. 훈련 과정 시각화하기
- 20. 모델 저장하고 복원하기
- 21. 시계열 데이터 예측하기
- 22. 자연어 처리하기 1
- 23. 자연어 처리하기 2
- 24. 자연어 처리하기 3
- 25. Reference
- tf.cast
- tf.constant
- tf.keras.activations.exponential
- tf.keras.activations.linear
- tf.keras.activations.relu
- tf.keras.activations.sigmoid
- tf.keras.activations.softmax
- tf.keras.activations.tanh
- tf.keras.datasets
- tf.keras.layers.Conv2D
- tf.keras.layers.Dense
- tf.keras.layers.Flatten
- tf.keras.layers.GlobalAveragePooling2D
- tf.keras.layers.InputLayer
- tf.keras.layers.ZeroPadding2D
- tf.keras.metrics.Accuracy
- tf.keras.metrics.BinaryAccuracy
- tf.keras.Sequential
- tf.linspace
- tf.ones
- tf.random.normal
- tf.range
- tf.rank
- tf.TensorShape
- tf.zeros
Tutorials
- Python Tutorial
- NumPy Tutorial
- Matplotlib Tutorial
- PyQt5 Tutorial
- BeautifulSoup Tutorial
- xlrd/xlwt Tutorial
- Pillow Tutorial
- Googletrans Tutorial
- PyWin32 Tutorial
- PyAutoGUI Tutorial
- Pyperclip Tutorial
- TensorFlow Tutorial
- Tips and Examples
4. 옵티마이저 사용하기¶
옵티마이저 (Optimizer)는 손실 함수을 통해 얻은 손실값으로부터 모델을 업데이트하는 방식을 의미합니다.
TensorFlow는 SGD, Adam, RMSprop과 같은 다양한 종류의 옵티마이저를 제공합니다.
옵티마이저의 기본 사용법을 알아보고, 훈련 과정에서 옵티마이저에 따라 모델의 손실값이 어떻게 감소하는지 확인해 보겠습니다.
■ Table of Contents
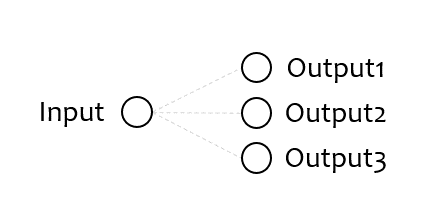
1) Neural Network 구성하기¶
이전 페이지에서와 마찬가지로 1개의 입력, 3개의 출력 노드를 갖는 신경망 모델을 구성합니다.
import tensorflow as tf
from tensorflow import keras
import numpy as np
tf.random.set_seed(0)
model = keras.Sequential([keras.layers.Dense(units=3, input_shape=[1])])
이번에는 tf.random 모듈의 set_seed() 함수를 사용해서 랜덤 시드를 설정했습니다.
tf.keras 모듈의 Sequantial 클래스는 Neural Network의 각 층을 순서대로 쌓을 수 있도록 합니다.
2) Neural Network 컴파일하기¶
구성한 모델의 손실 함수와 옵티마이저를 지정하기 위해 compile() 메서드를 사용합니다.
model.compile(loss='mse', optimizer='SGD')
손실 함수로 ‘mse’를, 옵티마이저로 ‘SGD’을 지정했습니다.
‘SGD’는 Stochastic Gradient Descent의 줄임말이며, 우리말로는 확률적 경사하강법이라고 부릅니다.
3) Neural Network 훈련하기¶
fit() 메서드는 컴파일 과정에서 지정한 손실 함수와 옵티마이저를 사용해서 모델을 훈련합니다.
model.fit([1], [[0, 1, 0]], epochs=1)
model.evaluate([1], [[0, 1, 0]])
1/1 [==============================] - 0s 1ms/step - loss: 1.0738
1/1 [==============================] - 0s 1ms/step - loss: 1.0453
1.0453256368637085
fit() 메서드는 훈련 진행 상황과 현재의 손실값을 반환합니다.
1회의 에포크 (epoch) 이후, evaluate() 메서드를 사용해서 손실값을 확인해보면
손실값이 1.0738에서 1.0453으로 감소했음을 알 수 있습니다.
history = model.fit([1], [[0, 1, 0]], epochs=100)
Epoch 1/100
1/1 [==============================] - 0s 1ms/step - loss: 1.0738
Epoch 2/100
1/1 [==============================] - 0s 1ms/step - loss: 1.0453
Epoch 3/100
1/1 [==============================] - 0s 982us/step - loss: 1.0176
.
.
.
Epoch 98/100
1/1 [==============================] - 0s 836us/step - loss: 0.0794
Epoch 99/100
1/1 [==============================] - 0s 1ms/step - loss: 0.0773
Epoch 100/100
1/1 [==============================] - 0s 1ms/step - loss: 0.0753
이번에는 훈련의 에포크를 100회로 지정했습니다.
100회 훈련 과정의 훈련 시간과 손실값이 출력됩니다.
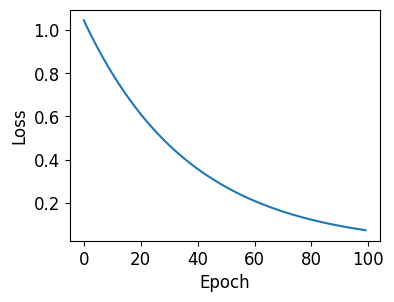
4) 손실값 시각화하기¶
import matplotlib.pyplot as plt
plt.style.use('default')
plt.rcParams['figure.figsize'] = (4, 3)
plt.rcParams['font.size'] = 12
loss = history.history['loss']
plt.plot(loss)
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.show()
fit() 메서드는 History 객체를 반환합니다.
History 객체의 history 속성은 훈련 과정의 손실값 (loss values)과 지표 (metrics)를 포함합니다.
컴파일 과정에서 지표를 지정하지 않았기 때문에 이 예제의 history 속성은 지표 (metrics)를 포함하지 않습니다.
훈련 과정의 손실값을 Matplotlib을 이용해서 그래프로 나타내면 아래와 같이 감소하는 경향을 확인할 수 있습니다.
5) 출력값 시각화하기¶
import tensorflow as tf
from tensorflow import keras
import matplotlib.pyplot as plt
import numpy as np
plt.style.use('default')
plt.rcParams['figure.figsize'] = (4, 3)
plt.rcParams['font.size'] = 12
tf.random.set_seed(0)
model = keras.Sequential([keras.layers.Dense(units=3, input_shape=[1], use_bias=False)])
model.compile(loss='mse', optimizer='SGD')
pred = model.predict([1])
print(pred)
print(model.get_weights())
plt.bar(np.arange(3), pred[0])
plt.ylim(-1.1, 1.1)
plt.xlabel('Output Node')
plt.ylabel('Output')
plt.text(-0.4, 0.8, 'Epoch 0')
plt.tight_layout()
plt.savefig('./plt/pred000.png')
plt.clf()
epochs = 500
for i in range(1, epochs+1):
model.fit([1], [[0, 1, 0]], epochs=1, verbose=0)
pred = model.predict([1])
if i % 25 == 0:
plt.bar(np.arange(3), pred[0])
plt.ylim(-1.1, 1.1)
plt.xlabel('Output Node')
plt.ylabel('Output')
plt.text(-0.4, 0.8, 'Epoch ' + str(i))
plt.tight_layout()
plt.savefig('./plt/pred' + str(i).zfill(3) + '.png')
plt.clf()
print(pred)
print(model.get_weights())
[[-0.5095548 -0.7187625 0.08668923]]
[array([[-0.5095548 , -0.7187625 , 0.08668923]], dtype=float32)]
[[-0.0179761 0.9393657 0.00305823]]
[array([[-0.0179761 , 0.9393657 , 0.00305823]], dtype=float32)]
이 코드는 Matplotlib을 이용해서 500회의 에포크 동안 훈련에 의해 출력값이 변화하는 과정을 시각화합니다.
Matplotlib의 다양한 함수에 대해서는 Matplotlib - 파이썬으로 그래프 그리기를 참고하세요.
아래 그림과 같이 훈련 과정 동안 출력값이 Target 값 [0, 1, 0]에 가까워지는 것을 알 수 있습니다.
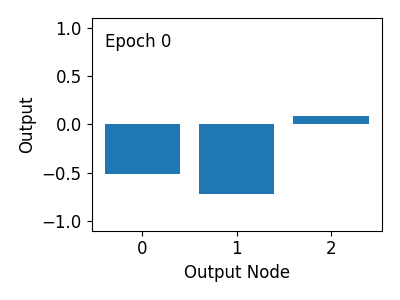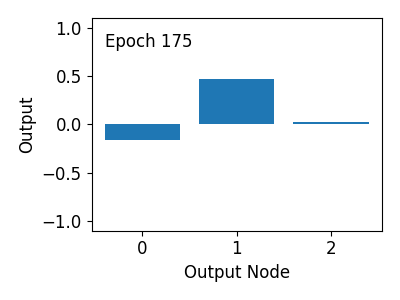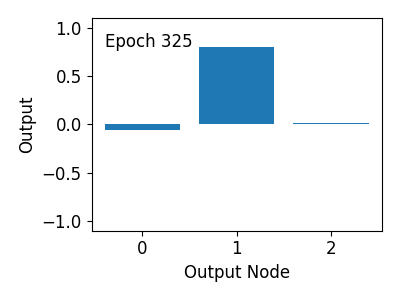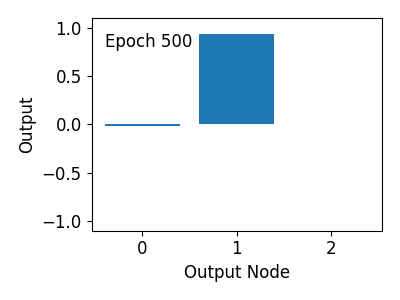
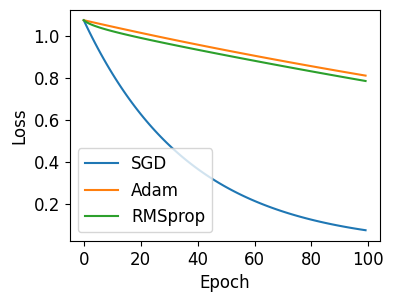
6) 옵티마이저 비교하기¶
아래의 예제는 세가지 옵티마이저 ‘SGD’, ‘Adam’, ‘RMSprop’이 모델을 업데이트하는 성능을 비교합니다.
import tensorflow as tf
from tensorflow import keras
import numpy as np
import matplotlib.pyplot as plt
plt.style.use('default')
plt.rcParams['figure.figsize'] = (4, 3)
plt.rcParams['font.size'] = 12
tf.random.set_seed(0)
model = keras.Sequential([keras.layers.Dense(units=3, input_shape=[1])])
tf.random.set_seed(0)
model2 = tf.keras.models.clone_model(model)
tf.random.set_seed(0)
model3 = tf.keras.models.clone_model(model)
model.compile(loss='mse', optimizer='SGD')
model2.compile(loss='mse', optimizer='Adam')
model3.compile(loss='mse', optimizer='RMSprop')
history = model.fit([1], [[0, 1, 0]], epochs=100, verbose=0)
history2 = model2.fit([1], [[0, 1, 0]], epochs=100, verbose=0)
history3 = model3.fit([1], [[0, 1, 0]], epochs=100, verbose=0)
loss = history.history['loss']
loss2 = history2.history['loss']
loss3 = history3.history['loss']
plt.plot(loss, label='SGD')
plt.plot(loss2, label='Adam')
plt.plot(loss3, label='RMSprop')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend(loc='lower left')
plt.show()
우선 세 개의 모델이 동일한 가중치 값을 갖도록 하기 위해 set_seed() 함수를 세번 호출했습니다.
compile() 메서드에 각각 다른 옵티마이저를 지정합니다.
100회 훈련 과정의 손실값을 시각화하면 아래와 같습니다.
옵티마이저에 따라 모델을 업데이트하는 방식과 손실값이 감소하는 경향에 차이가 있음을 알 수 있습니다.