Contents
- TensorFlow - 구글 머신러닝 플랫폼
- 1. 텐서 기초 살펴보기
- 2. 간단한 신경망 만들기
- 3. 손실 함수 살펴보기
- 4. 옵티마이저 사용하기
- 5. AND 로직 연산 학습하기
- 6. 뉴런층의 속성 확인하기
- 7. 뉴런층의 출력 확인하기
- 8. MNIST 손글씨 이미지 분류하기
- 9. Fashion MNIST 이미지 분류하기
- 10. 합성곱 신경망 사용하기
- 11. 말과 사람 이미지 분류하기
- 12. 고양이와 개 이미지 분류하기
- 13. 이미지 어그멘테이션의 효과
- 14. 전이 학습 활용하기
- 15. 다중 클래스 분류 문제
- 16. 시냅스 가중치 얻기
- 17. 시냅스 가중치 적용하기
- 18. 모델 시각화하기
- 19. 훈련 과정 시각화하기
- 20. 모델 저장하고 복원하기
- 21. 시계열 데이터 예측하기
- 22. 자연어 처리하기 1
- 23. 자연어 처리하기 2
- 24. 자연어 처리하기 3
- 25. Reference
- tf.cast
- tf.constant
- tf.keras.activations.exponential
- tf.keras.activations.linear
- tf.keras.activations.relu
- tf.keras.activations.sigmoid
- tf.keras.activations.softmax
- tf.keras.activations.tanh
- tf.keras.datasets
- tf.keras.layers.Conv2D
- tf.keras.layers.Dense
- tf.keras.layers.Flatten
- tf.keras.layers.GlobalAveragePooling2D
- tf.keras.layers.InputLayer
- tf.keras.layers.ZeroPadding2D
- tf.keras.metrics.Accuracy
- tf.keras.metrics.BinaryAccuracy
- tf.keras.Sequential
- tf.linspace
- tf.ones
- tf.random.normal
- tf.range
- tf.rank
- tf.TensorShape
- tf.zeros
Tutorials
- Python Tutorial
- NumPy Tutorial
- Matplotlib Tutorial
- PyQt5 Tutorial
- BeautifulSoup Tutorial
- xlrd/xlwt Tutorial
- Pillow Tutorial
- Googletrans Tutorial
- PyWin32 Tutorial
- PyAutoGUI Tutorial
- Pyperclip Tutorial
- TensorFlow Tutorial
- Tips and Examples
다변량 시계열 데이터 예측하기¶
각 시간 단위마다 여러 개의 값을 가지는 데이터를 다변량 시계열 데이터 (Multivariate Time Series Data)라고 합니다.
시간 단위는 시 (hour), 분 (minute), 초 (second) 또는 월 (month), 연도 (year) 등 다양한 단위를 가질 수 있습니다.
이번에는 TensorFlow를 이용해서 다변량 시계열 데이터에 대한 예측을 진행해 보겠습니다.
날씨 데이터셋 페이지에서 소개했던 원본 날씨 데이터셋은 14개의 날씨 속성을 갖고 있습니다.
예제에서는 문제를 간단하게 하게 위해 14개 중 온도 (air temperature), 기압 (atmospheric pressure), 공기밀도 (air density) 데이터 세가지 속성을 다룹니다.
앞의 예제에서와 같이 데이터 프레임 (df)에서 세 개의 열을 얻습니다.
features_considered = ['p (mbar)', 'T (degC)', 'rho (g/m**3)']
features = df[features_considered]
features.index = df['Date Time']
print(features.head())
p (mbar) T (degC) rho (g/m\*\*3)
Date Time
01.01.2009 00:10:00 996.52 -8.02 1307.75
01.01.2009 00:20:00 996.57 -8.41 1309.80
01.01.2009 00:30:00 996.53 -8.51 1310.24
01.01.2009 00:40:00 996.51 -8.31 1309.19
01.01.2009 00:50:00 996.51 -8.27 1309.00
기압, 온도, 공기밀도의 순서로 데이터가 출력되었습니다.
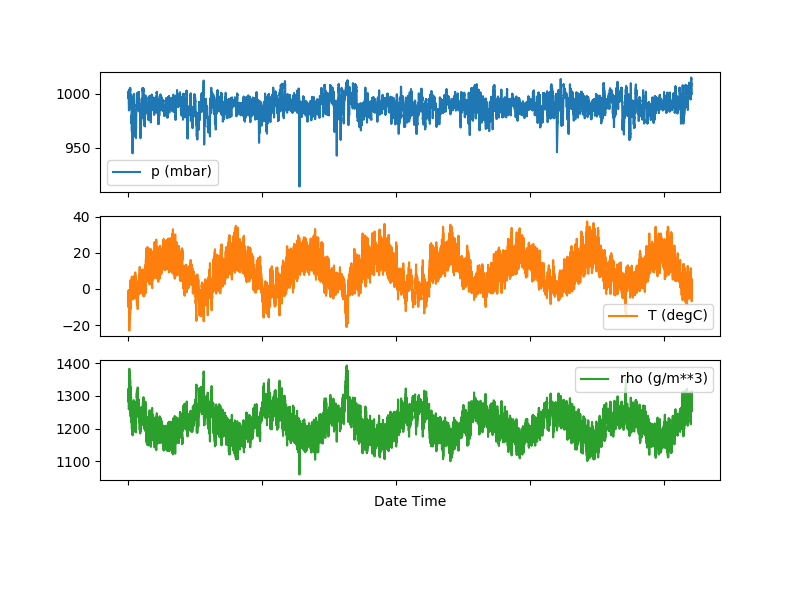
features.plot(subplots=True)
plt.show()
그래프로 나타내면 아래와 같습니다.
표준화 (Standardization)¶
앞에서와 마찬가지로, 세가지 종류의 데이터에 대해서 평균을 빼고 표준편차로 나누어줌으로써 표준화를 진행합니다.
dataset = features.values
data_mean = dataset[:TRAIN_SPLIT].mean(axis=0)
data_std = dataset[:TRAIN_SPLIT].std(axis=0)
dataset = (dataset-data_mean)/data_std
print(dataset)
[[ 0.95547359 -1.99766294 2.2350791 ]
[ 0.96154485 -2.04281897 2.28524007]
[ 0.95668784 -2.05439744 2.29600633]
...
[ 1.35617678 -1.43494935 1.76136375]
[ 1.35496252 -1.55883897 1.88786728]
[ 1.35617678 -1.62715193 1.95686921]]
한 스텝 예측 (Single step model)¶
이제 신경망 모델은 주어진 과거의 자료로부터 하나의 포인트를 예측하는 것을 학습합니다.
아래의 multivariate_data 함수는 univariate_data 함수와 비슷하게 동작하지만 step 값이 주어진다면 step에 맞게 데이터를 샘플링합니다.
def multivariate_data(dataset, target, start_index, end_index, history_size, target_size, step, single_step=False)
data = []
labels = []
start_index = start_index + history_size
if end_index is None:
end_index = len(dataset) - target_size
for i in range(start_index, end_index):
indices = range(i - history_size, i, step)
data.append(dataset[indices])
if single_step:
labels.append(target[i + target_size])
else:
labels.append(target[i:i + target_size])
return np.array(data), np.array(labels)
past_history = 720
future_target = 72
STEP = 6
x_train_single, y_train_single = multivariate_data(dataset, dataset[:, 1], 0, TRAIN_SPLIT, past_history,
future_target, STEP, single_step=True)
x_val_single, y_val_single = multivariate_data(dataset, dataset[:, 1], TRAIN_SPLIT, None, past_history,
future_target, STEP, single_step=True)
print('Single window of past history : {}'.format(x_train_single[0].shape))
Single window of past history : (120, 3)
past_history는 지난 5일간의 데이터입니다. (720 = 5일 * 144개, 144 = 6개 * 24시간)
future_target은 72시간 스텝 이후 (12시간)를 예측할 것임을 의미합니다.
STEP은 샘플링 간격을 의미합니다.
train_data_single = tf.data.Dataset.from_tensor_slices((x_train_single, y_train_single))
train_data_single = train_data_single.cache().shuffle(BUFFER_SIZE).batch(BATCH_SIZE).repeat()
val_data_single = tf.data.Dataset.from_tensor_slices((x_val_single, y_val_single))
val_data_single = val_data_single.batch(BATCH_SIZE).repeat()
single_step_model = tf.keras.models.Sequential()
single_step_model.add(tf.keras.layers.LSTM(32, input_shape=x_train_single.shape[-2:]))
single_step_model.add(tf.keras.layers.Dense(1))
single_step_model.compile(optimizer=tf.keras.optimizers.RMSprop(), loss='mae')
for x, y in val_data_single.take(1):
print(single_step_model.predict(x).shape)
single_step_history = single_step_model.fit(train_data_single, epochs=EPOCHS,
steps_per_epoch=EVALUATION_INTERVAL,
validation_data=val_data_single,
validation_steps=50)
def plot_train_history(history, title):
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(len(loss))
plt.figure()
plt.plot(epochs, loss, 'b', label='Training loss')
plt.plot(epochs, val_loss, 'r', label='Validation loss')
plt.title(title)
plt.legend()
plt.show()
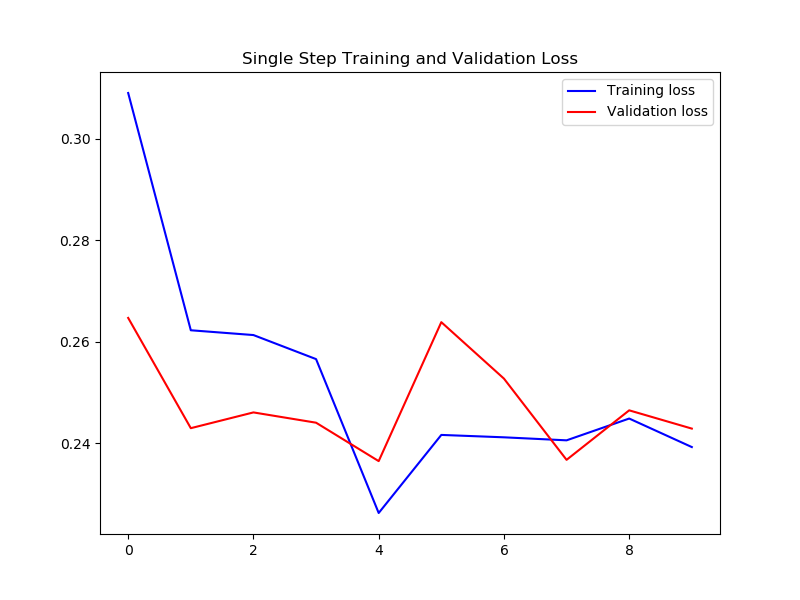
plot_train_history(single_step_history,
'Single Step Training and Validation Loss')
다변량 시계열 데이터의 한 스텝 예측을 위한 인공신경망 모델을 구성하고,
10회 에포크의 학습을 진행합니다.
plot_train_history 함수는 학습 과정을 그래프로 표헌합니다.
결과는 아래와 같습니다.
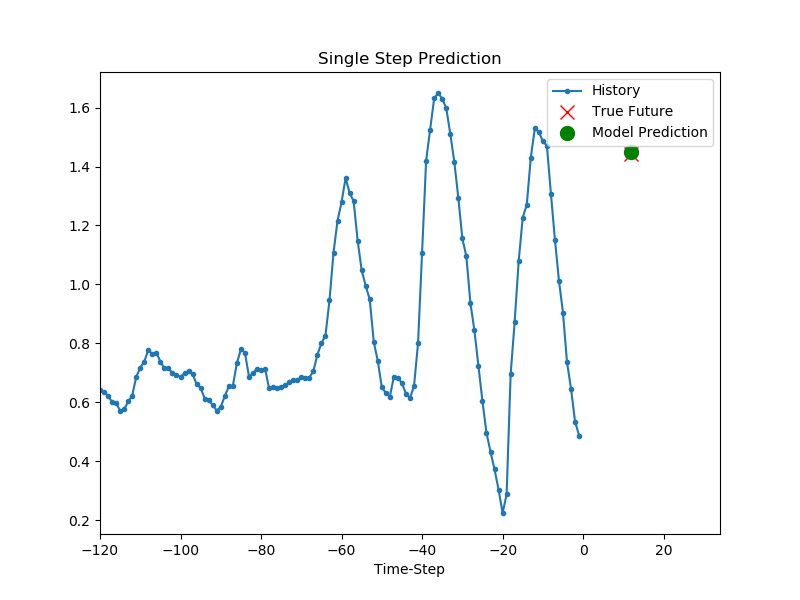
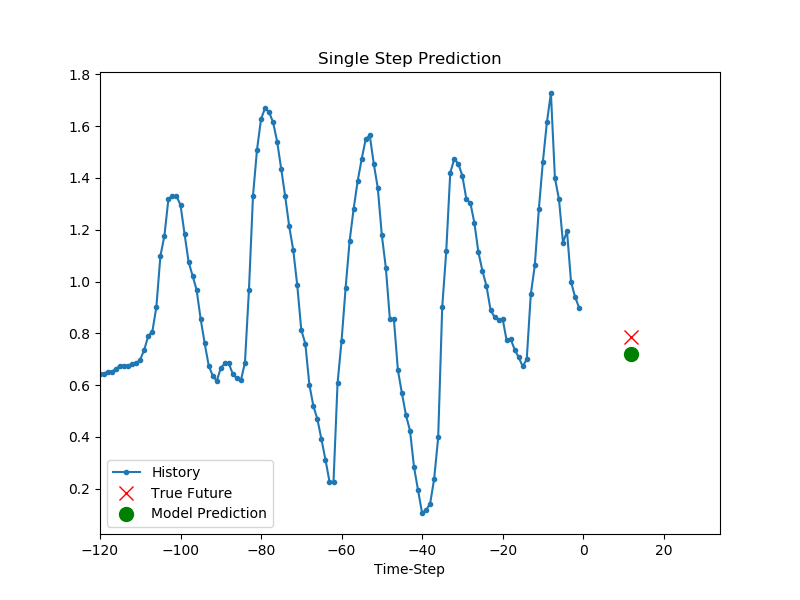
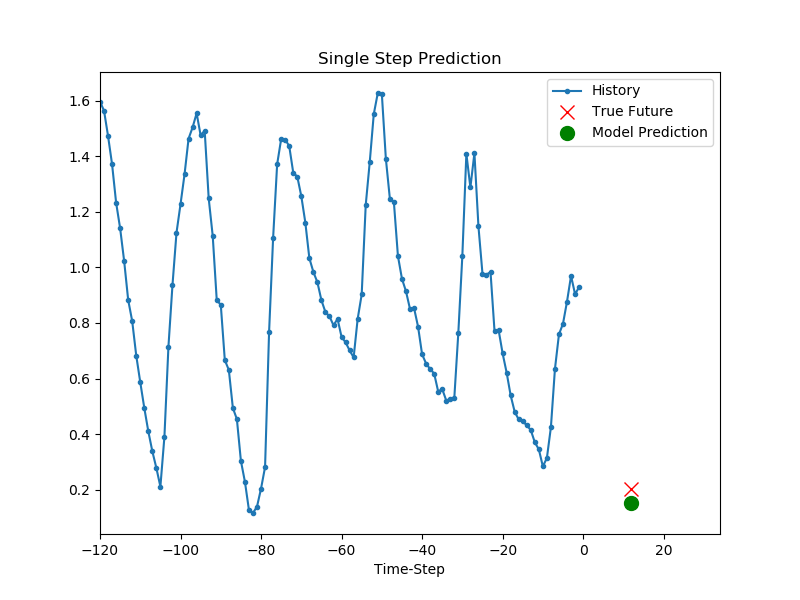
for x, y in val_data_single.take(3):
plot = show_plot([x[0][:, 1].numpy(), y[0].numpy(),
single_step_model.predict(x)[0]], 12,
'Single Step Prediction')
plot.show()
모델이 학습되었다면 한 스텝 예측을 진행할 수 있습니다.
모델에는 지난 5일 간 매시간 측정된 세가지 종류의 각 120개의 데이터가 주어지고, 12시간 후의 온도를 예측하는 것을 목표로 합니다.
결과는 아래와 같습니다.
past_history = 720
future_target = 72
STEP = 6
x_train_multi, y_train_multi = multivariate_data(dataset, dataset[:, 1], 0,
TRAIN_SPLIT, past_history, future_target, STEP)
x_val_multi, y_val_multi = multivariate_data(dataset, dataset[:, 1],
TRAIN_SPLIT, None, past_history, future_target, STEP)
print('Single window of past history : {}'.format(x_train_multi[0].shape))
print('\n Target temperature to predict : {}'.format(y_train_multi[0].shape))
Single window of past history : (120, 3)
Target temperature to predict : (72,)