Contents
- TensorFlow - 구글 머신러닝 플랫폼
- 1. 텐서 기초 살펴보기
- 2. 간단한 신경망 만들기
- 3. 손실 함수 살펴보기
- 4. 옵티마이저 사용하기
- 5. AND 로직 연산 학습하기
- 6. 뉴런층의 속성 확인하기
- 7. 뉴런층의 출력 확인하기
- 8. MNIST 손글씨 이미지 분류하기
- 9. Fashion MNIST 이미지 분류하기
- 10. 합성곱 신경망 사용하기
- 11. 말과 사람 이미지 분류하기
- 12. 고양이와 개 이미지 분류하기
- 13. 이미지 어그멘테이션의 효과
- 14. 전이 학습 활용하기
- 15. 다중 클래스 분류 문제
- 16. 시냅스 가중치 얻기
- 17. 시냅스 가중치 적용하기
- 18. 모델 시각화하기
- 19. 훈련 과정 시각화하기
- 20. 모델 저장하고 복원하기
- 21. 시계열 데이터 예측하기
- 22. 자연어 처리하기 1
- 23. 자연어 처리하기 2
- 24. 자연어 처리하기 3
- 25. Reference
- tf.cast
- tf.constant
- tf.keras.activations.exponential
- tf.keras.activations.linear
- tf.keras.activations.relu
- tf.keras.activations.sigmoid
- tf.keras.activations.softmax
- tf.keras.activations.tanh
- tf.keras.datasets
- tf.keras.layers.Conv2D
- tf.keras.layers.Dense
- tf.keras.layers.Flatten
- tf.keras.layers.GlobalAveragePooling2D
- tf.keras.layers.InputLayer
- tf.keras.layers.ZeroPadding2D
- tf.keras.metrics.Accuracy
- tf.keras.metrics.BinaryAccuracy
- tf.keras.Sequential
- tf.linspace
- tf.ones
- tf.random.normal
- tf.range
- tf.rank
- tf.TensorShape
- tf.zeros
Tutorials
- Python Tutorial
- NumPy Tutorial
- Matplotlib Tutorial
- PyQt5 Tutorial
- BeautifulSoup Tutorial
- xlrd/xlwt Tutorial
- Pillow Tutorial
- Googletrans Tutorial
- PyWin32 Tutorial
- PyAutoGUI Tutorial
- Pyperclip Tutorial
- TensorFlow Tutorial
- Tips and Examples
12. 고양이와 개 이미지 분류하기¶

이전의 예제에서 다루었던 MNIST, Fashion MNIST 데이터셋은 이미지 패턴이 비교적 단순하며 흑백의 색상을 가지고, 이미지가 모두 같은 크기를 가지기 때문에 상대적으로 쉬운 문제로 알려져 있습니다.
하지만 현실의 이미지 분류 문제는 이와 달리 더 복잡한 패턴을 가지거나 다양한 색상을 가지고, 또한 이미지의 크기가 달라질 수 있습니다.
이번 페이지에서는 잘 알려진 이미지 분류 문제인 Kaggle Dogs Vs. Cats 데이터셋을 살펴보고, Neural Network를 구성하고 훈련시켜서, 정확도를 확인하는 과정에 대해 순서대로 소개합니다.
또한 이번에는 Google Colab (Colaboratory)을 사용해서 웹브라우저 상에서 특별한 환경 구성없이 머신러닝 코드를 작성해 보겠습니다. Google Colab에 대해서는 Google Colab 소개 페이지를 참고하세요.
순서는 아래와 같습니다.
Kaggle Dogs Vs. Cats 데이터셋 준비하기¶
Kaggle (캐글)은 데이터 사이언스와 머신러닝 경진대회를 위한 플랫폼입니다.
머신러닝 학습과 해결, 경쟁을 위한 다양한 데이터셋을 제공하며, 2017년 3월 Google에 인수되었습니다.
Dogs Vs. Cats 데이터셋은 Kaggle에서 다루었던 Challenge 중 하나였습니다.
현재 이 Challenge는 종료되었고, 순위는 아래와 같습니다.

다운로드하기¶
!wget --no-check-certificate \
https://storage.googleapis.com/mledu-datasets/cats_and_dogs_filtered.zip \
-O /tmp/cats_and_dogs_filtered.zip
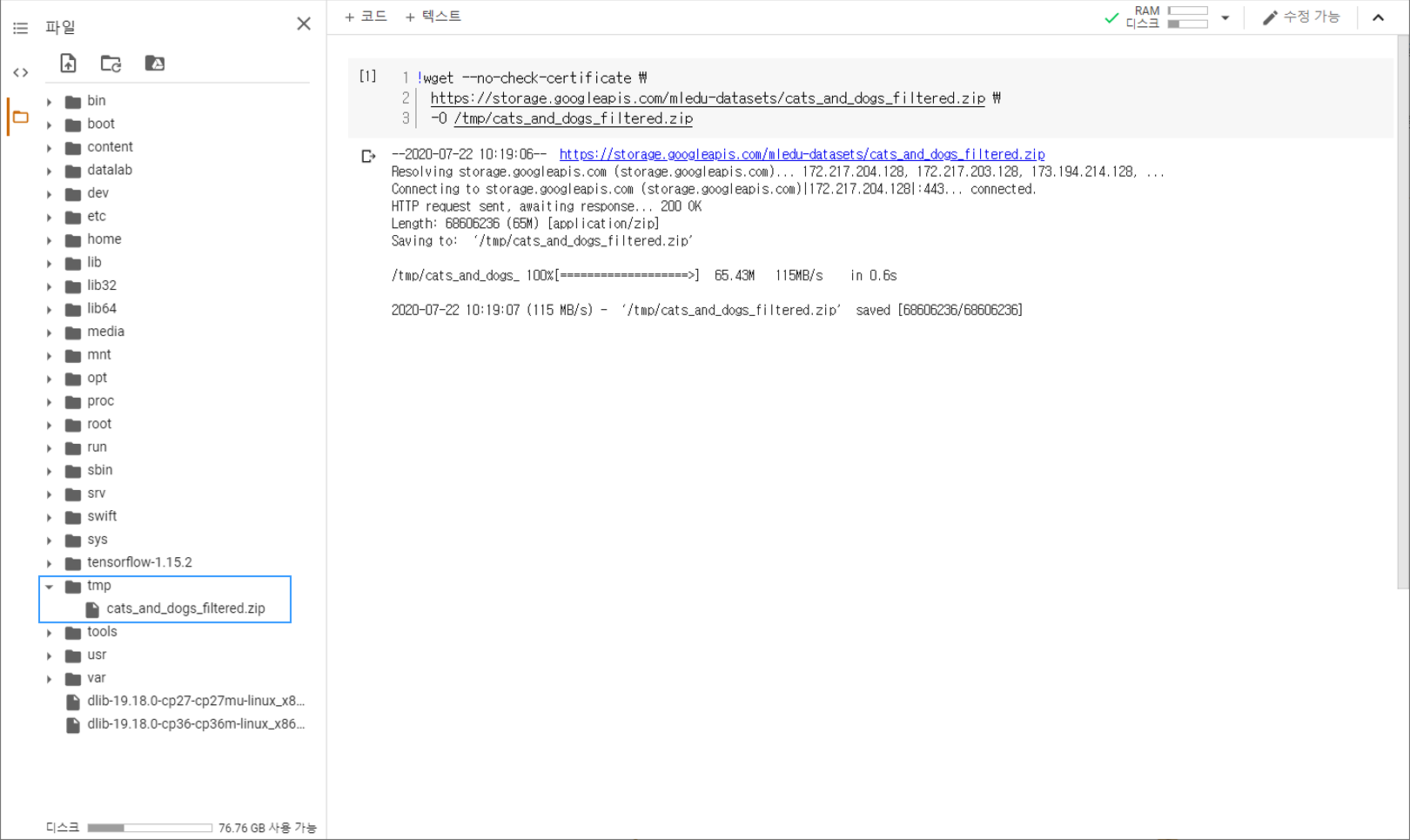
우선 Colab 코드셀에 위의 명령어를 입력해서 데이터셋을 다운로드합니다.
아래 그림과 같이 페이지 왼쪽의 목차 탭을 열어서 tmp 폴더에
cats_and_dogs_filtered.zip 파일이 다운로드되어 있는지 확인합니다.
cats_and_dogs_filtered 데이터셋은 25,000개의 이미지를 포함하는 원본 Dogs Vs. Cats 데이터셋에서 약 3,000개의 이미지를 추출한 간소화된 버전의 데이터셋입니다.
압축풀기¶
import os
import zipfile
local_zip = '/tmp/cats_and_dogs_filtered.zip'
zip_ref = zipfile.ZipFile(local_zip, 'r')
zip_ref.extractall('/tmp')
zip_ref.close()
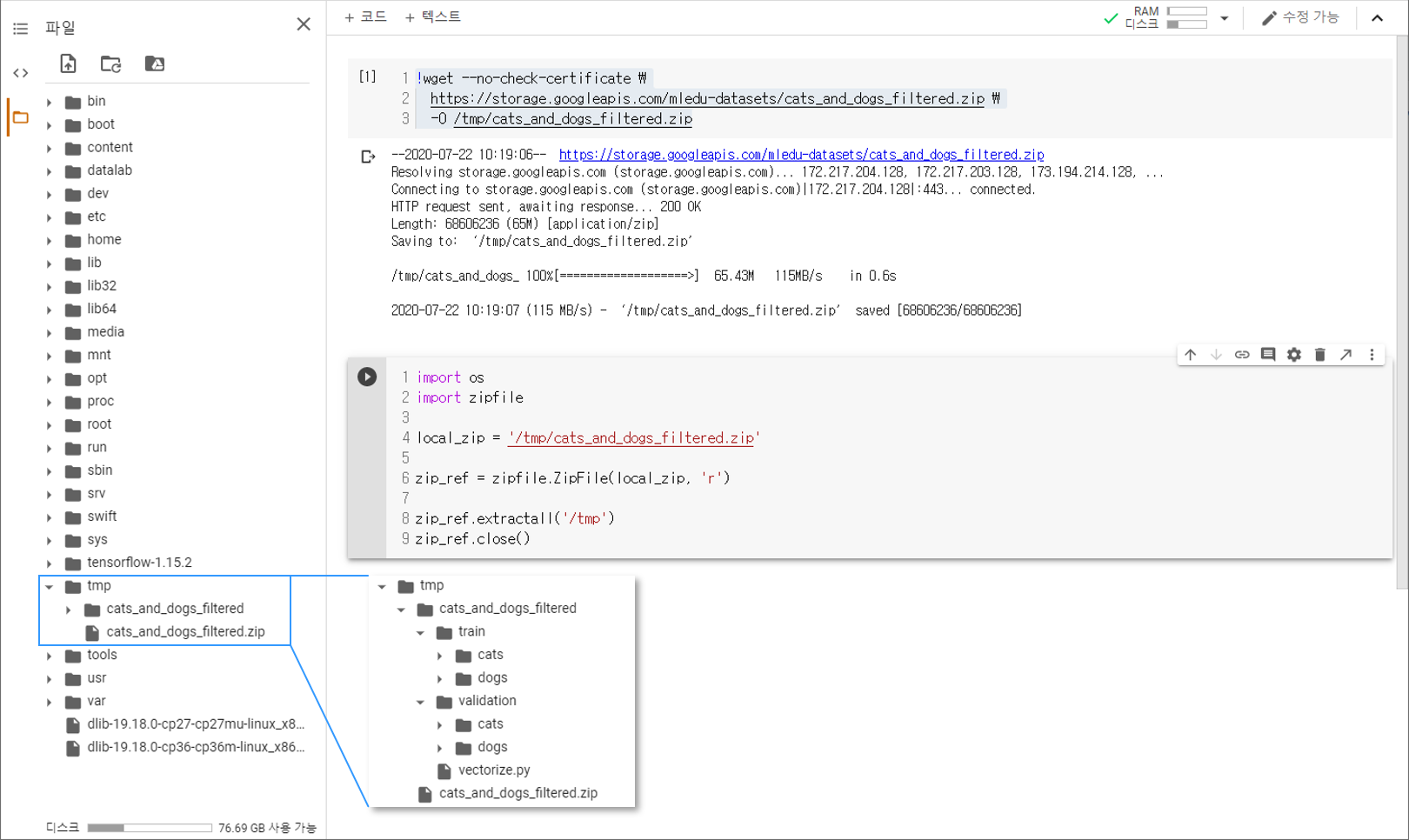
os 라이브러리를 통해 파일시스템에 접근할 수 있습니다.
zipfile 라이브러리의 ZipFile 클래스로 ZIP 파일을 연 후에
extractall() 메서드를 이용해서 tmp 폴더에 압축을 풉니다.
아래 그림과 같이 cats_and_dogs_filtered 폴더가 만들어졌다면 준비가 된 것입니다.
경로 지정하기¶
# 기본 경로
base_dir = '/tmp/cats_and_dogs_filtered'
train_dir = os.path.join(base_dir, 'train')
validation_dir = os.path.join(base_dir, 'validation')
# 훈련에 사용되는 고양이/개 이미지 경로
train_cats_dir = os.path.join(train_dir, 'cats')
train_dogs_dir = os.path.join(train_dir, 'dogs')
print(train_cats_dir)
print(train_dogs_dir)
# 테스트에 사용되는 고양이/개 이미지 경로
validation_cats_dir = os.path.join(validation_dir, 'cats')
validation_dogs_dir = os.path.join(validation_dir, 'dogs')
print(validation_cats_dir)
print(validation_dogs_dir)
/tmp/cats_and_dogs_filtered/train/cats
/tmp/cats_and_dogs_filtered/train/dogs
/tmp/cats_and_dogs_filtered/validation/cats
/tmp/cats_and_dogs_filtered/validation/dogs
기본 경로와 훈련에 사용되는 고양이/개 이미지의 경로를 각각 지정해줍니다.
Kaggle Dogs Vs. Cats 데이터셋 살펴보기¶
파일 이름과 개수¶
train_cat_fnames = os.listdir( train_cats_dir )
train_dog_fnames = os.listdir( train_dogs_dir )
print(train_cat_fnames[:5])
print(train_dog_fnames[:5])
['cat.702.jpg', 'cat.589.jpg', 'cat.788.jpg', 'cat.951.jpg', 'cat.265.jpg']
['dog.776.jpg', 'dog.573.jpg', 'dog.575.jpg', 'dog.405.jpg', 'dog.439.jpg']
os.listdir() 메서드는 경로 내에 있는 파일의 이름을 리스트의 형태로 반환합니다.
각각 다섯 개씩 출력했습니다.
print('Total training cat images :', len(os.listdir(train_cats_dir)))
print('Total training dog images :', len(os.listdir(train_dogs_dir)))
print('Total validation cat images :', len(os.listdir(validation_cats_dir)))
print('Total validation dog images :', len(os.listdir(validation_dogs_dir)))
Total training cat images : 1000
Total training dog images : 1000
Total validation cat images : 500
Total validation dog images : 500
각 경로에 있는 파일명 리스트의 길이를 통해 파일의 개수를 확인합니다.
이미지 확인하기¶
%matplotlib inline
import matplotlib.image as mpimg
import matplotlib.pyplot as plt
nrows, ncols = 4, 4
pic_index = 0
fig = plt.gcf()
fig.set_size_inches(ncols*3, nrows*3)
pic_index+=8
next_cat_pix = [os.path.join(train_cats_dir, fname)
for fname in train_cat_fnames[ pic_index-8:pic_index]]
next_dog_pix = [os.path.join(train_dogs_dir, fname)
for fname in train_dog_fnames[ pic_index-8:pic_index]]
for i, img_path in enumerate(next_cat_pix+next_dog_pix):
sp = plt.subplot(nrows, ncols, i + 1)
sp.axis('Off')
img = mpimg.imread(img_path)
plt.imshow(img)
plt.show()
Matplotlib 라이브러리를 이용해서 이미지를 출력해보면, 데이터셋에 아래와 같은 이미지들이 포함되어 있음을 알 수 있습니다.

모델 구성하기¶
import tensorflow as tf
model = tf.keras.models.Sequential([
tf.keras.layers.Conv2D(16, (3,3), activation='relu', input_shape=(150, 150, 3)),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Conv2D(32, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Conv2D(64, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(512, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid')
])
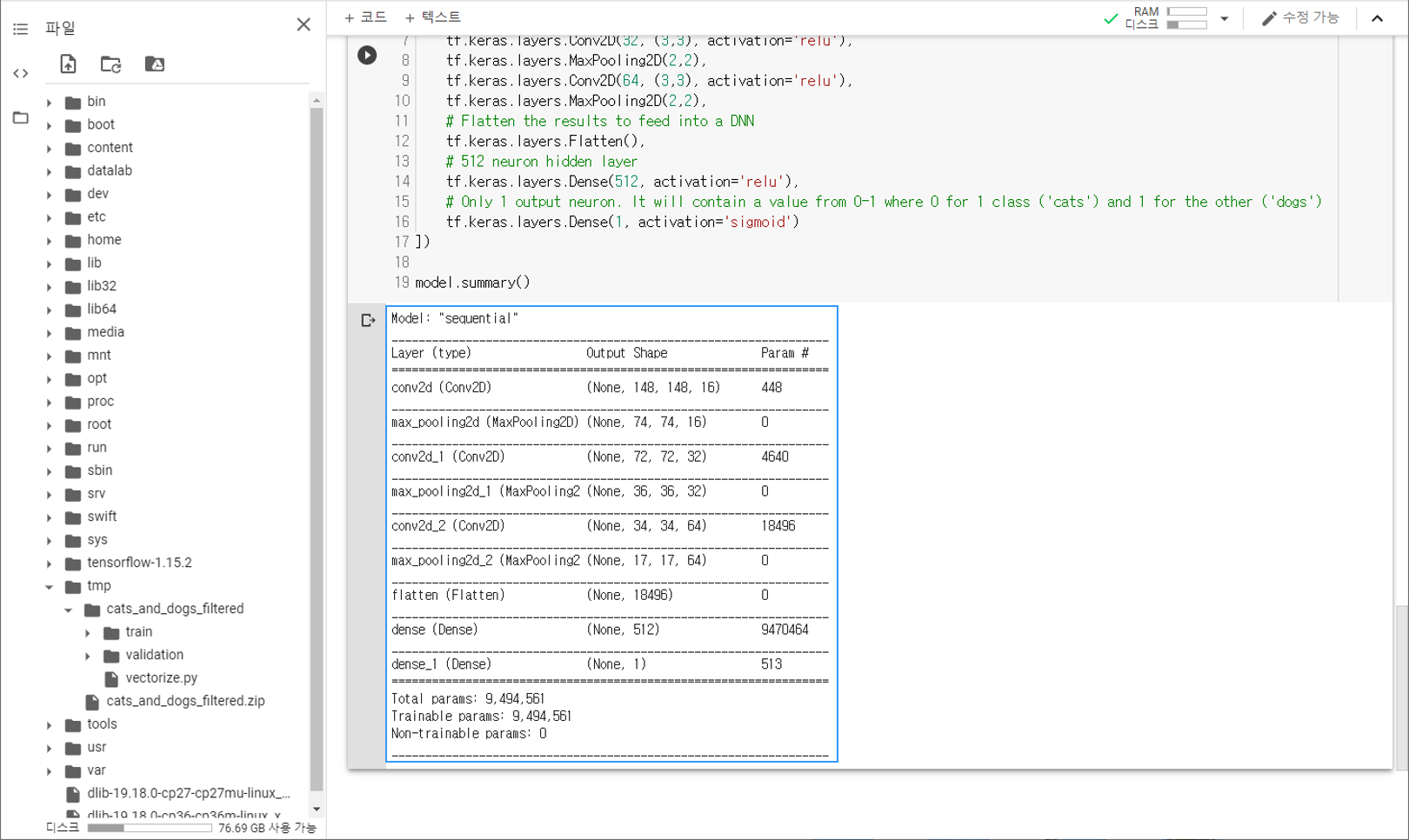
model.summary()
이제 TensorFlow를 이용해서 합성곱 신경망의 모델을 구성합니다.
summary() 메서드를 이용해서 신경망의 구조를 확인할 수 있습니다.
모델 컴파일하기¶
from tensorflow.keras.optimizers import RMSprop
model.compile(optimizer=RMSprop(lr=0.001),
loss='binary_crossentropy',
metrics = ['accuracy'])
모델 컴파일 단계에서는 compile() 메서드를 이용해서 손실 함수 (loss function)와 옵티마이저 (optimizer)를 지정합니다.
말과 사람 이미지 분류하기 예제에서와 같이 손실 함수로 ‘binary_crossentropy’를 사용했습니다.
출력층의 활성화함수로 ‘sigmoid’를 사용했고, 이는 0과 1 두 가지로 분류되는 ‘binary’ 분류 문제에 적합하기 때문입니다.
또한, 옵티마이저로는 RMSprop을 사용했습니다.
RMSprop (Root Mean Square Propagation) Algorithm은 훈련 과정 중에 학습률을 적절하게 변화시킵니다.
이미지 데이터 전처리하기¶
훈련을 진행하기 전, tf.keras.preprocessing.image 모듈의 ImageDataGenerator 클래스를 이용해서 데이터 전처리를 진행합니다.
from tensorflow.keras.preprocessing.image import ImageDataGenerator
train_datagen = ImageDataGenerator( rescale = 1.0/255. )
test_datagen = ImageDataGenerator( rescale = 1.0/255. )
train_generator = train_datagen.flow_from_directory(train_dir,
batch_size=20,
class_mode='binary',
target_size=(150, 150))
validation_generator = test_datagen.flow_from_directory(validation_dir,
batch_size=20,
class_mode = 'binary',
target_size = (150, 150))
Found 2000 images belonging to 2 classes.
Found 1000 images belonging to 2 classes.
우선 ImageDataGenerator 객체의 rescale 파라미터를 이용해서 모든 데이터를 255로 나누어준 다음,
flow_from_directory() 메서드를 이용해서 훈련과 테스트에 사용될 이미지 데이터를 만듭니다.
첫번째 인자로 이미지들이 위치한 경로를 입력하고, batch_size, class_mode를 지정합니다.
target_size에 맞춰서 이미지의 크기가 조절됩니다.
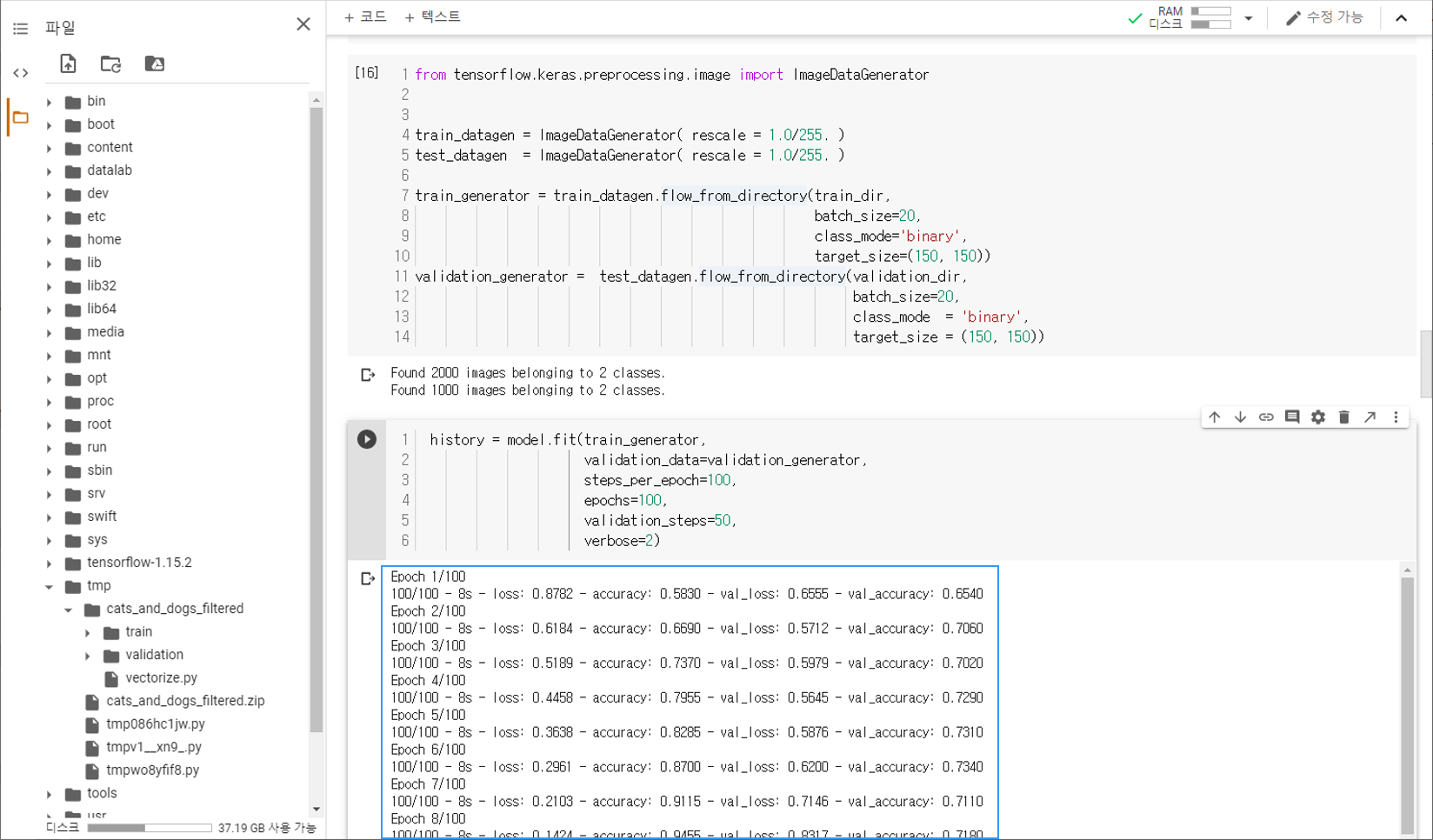
모델 훈련하기¶
fit() 메서드는 앞에서 구성한 Neural Network 모델을 훈련합니다.
history = model.fit(train_generator,
validation_data=validation_generator,
steps_per_epoch=100,
epochs=100,
validation_steps=50,
verbose=2)
훈련과 테스트를 위한 데이터셋인 train_generator, validation_generator를 입력합니다.
epochs는 데이터셋을 한 번 훈련하는 과정을 의미합니다.
steps_per_epoch는 한 번의 에포크 (epoch)에서 훈련에 사용할 배치 (batch)의 개수를 지정합니다.
validation_steps는 한 번의 에포크가 끝날 때, 테스트에 사용되는 배치 (batch)의 개수를 지정합니다.
아래와 같은 훈련 과정을 확인할 수 있습니다.
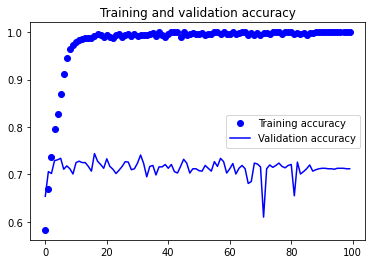
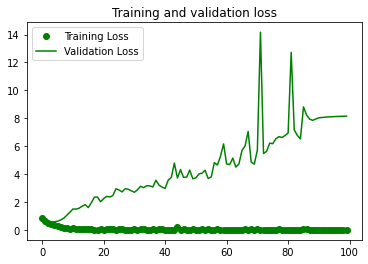
정확도와 손실 확인하기¶
import matplotlib.pyplot as plt
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(len(acc))
plt.plot(epochs, acc, 'bo', label='Training accuracy')
plt.plot(epochs, val_acc, 'b', label='Validation accuracy')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'go', label='Training Loss')
plt.plot(epochs, val_loss, 'g', label='Validation Loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()
Matplotlib 라이브러리를 이용해서 훈련 과정에서 에포크에 따른 정확도와 손실을 출력합니다.
아래와 같은 이미지가 출력됩니다.
20회 에포크에서 훈련 정확도는 1.0에 근접한 반면, 테스트의 정확도는 100회 훈련이 끝나도 0.7 수준에 머물고 있습니다.
이러한 현상을 과적합 (Overfitting)이라고 합니다.
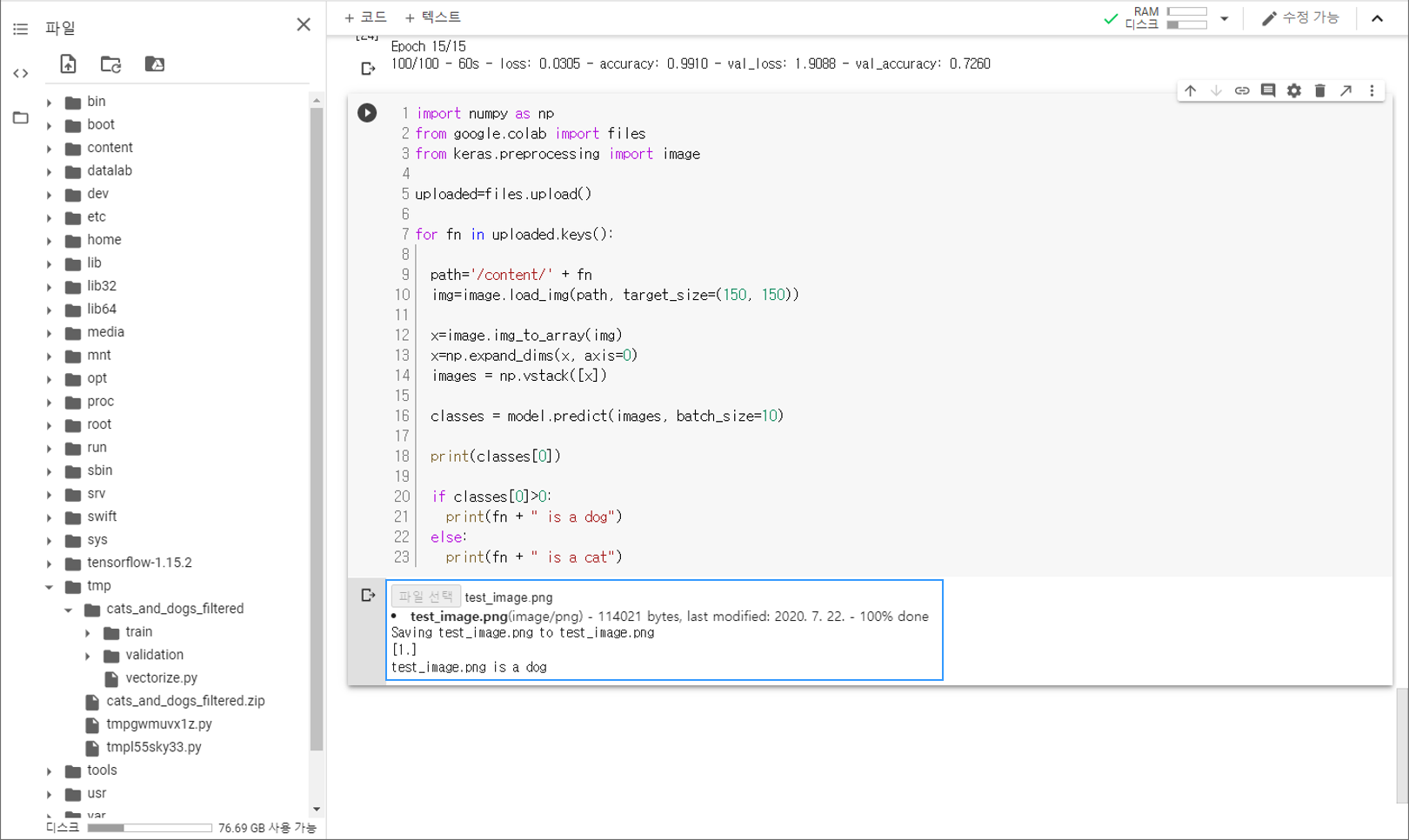
테스트 이미지 분류하기¶
아래의 테스트 이미지를 사용해서 훈련된 모델이 개와 고양이 이미지를 분류할 수 있는지 확인해 보겠습니다.

test_image.png¶
import numpy as np
from google.colab import files
from keras.preprocessing import image
uploaded=files.upload()
for fn in uploaded.keys():
path='/content/' + fn
img=image.load_img(path, target_size=(150, 150))
x=image.img_to_array(img)
x=np.expand_dims(x, axis=0)
images = np.vstack([x])
classes = model.predict(images, batch_size=10)
print(classes[0])
if classes[0]>0:
print(fn + " is a dog")
else:
print(fn + " is a cat")
이 코드는 하나 이상의 이미지를 업로드하고, 훈련된 모델을 사용해서 개/고양이 분류 결과를 출력합니다.
결과는 아래와 같습니다.