Contents
- TensorFlow - 구글 머신러닝 플랫폼
- 1. 텐서 기초 살펴보기
- 2. 간단한 신경망 만들기
- 3. 손실 함수 살펴보기
- 4. 옵티마이저 사용하기
- 5. AND 로직 연산 학습하기
- 6. 뉴런층의 속성 확인하기
- 7. 뉴런층의 출력 확인하기
- 8. MNIST 손글씨 이미지 분류하기
- 9. Fashion MNIST 이미지 분류하기
- 10. 합성곱 신경망 사용하기
- 11. 말과 사람 이미지 분류하기
- 12. 고양이와 개 이미지 분류하기
- 13. 이미지 어그멘테이션의 효과
- 14. 전이 학습 활용하기
- 15. 다중 클래스 분류 문제
- 16. 시냅스 가중치 얻기
- 17. 시냅스 가중치 적용하기
- 18. 모델 시각화하기
- 19. 훈련 과정 시각화하기
- 20. 모델 저장하고 복원하기
- 21. 시계열 데이터 예측하기
- 22. 자연어 처리하기 1
- 23. 자연어 처리하기 2
- 24. 자연어 처리하기 3
- 25. Reference
- tf.cast
- tf.constant
- tf.keras.activations.exponential
- tf.keras.activations.linear
- tf.keras.activations.relu
- tf.keras.activations.sigmoid
- tf.keras.activations.softmax
- tf.keras.activations.tanh
- tf.keras.datasets
- tf.keras.layers.Conv2D
- tf.keras.layers.Dense
- tf.keras.layers.Flatten
- tf.keras.layers.GlobalAveragePooling2D
- tf.keras.layers.InputLayer
- tf.keras.layers.ZeroPadding2D
- tf.keras.metrics.Accuracy
- tf.keras.metrics.BinaryAccuracy
- tf.keras.Sequential
- tf.linspace
- tf.ones
- tf.random.normal
- tf.range
- tf.rank
- tf.TensorShape
- tf.zeros
Tutorials
- Python Tutorial
- NumPy Tutorial
- Matplotlib Tutorial
- PyQt5 Tutorial
- BeautifulSoup Tutorial
- xlrd/xlwt Tutorial
- Pillow Tutorial
- Googletrans Tutorial
- PyWin32 Tutorial
- PyAutoGUI Tutorial
- Pyperclip Tutorial
- TensorFlow Tutorial
- Tips and Examples
9. Fashion MNIST 이미지 분류하기¶

Fashion MNIST 이미지 데이터셋.¶
Fashion MNIST 데이터셋은 위 그림과 같이 운동화, 셔츠, 샌들과 같은 작은 이미지들의 모음이며, 기본 MNIST 데이터셋과 같이 열 가지로 분류될 수 있는 28×28 픽셀의 이미지 70,000개로 이루어져 있습니다.
이번 페이지에서는 Dense 층들로 구성되는 Fully-Connected Neural Network (완전 연결된 인공신경망)을 이용해서 Fashion MNIST 데이터셋을 분류해 보겠습니다.
순서는 아래와 같습니다.
Fashion MNIST 데이터셋 불러오기¶
import tensorflow as tf
# 1. Fashion MNIST 데이터셋 불러오기
fashion_mnist = tf.keras.datasets.fashion_mnist
(train_images, train_labels), (test_images, test_labels) = fashion_mnist.load_data()
tf.keras.datasets 모듈은 Neural Network의 훈련에 사용할 수 있는 여러 데이터셋을 포함합니다.
아래와 같은 7가지의 데이터셋이 있습니다.
예제에서는 fashion_mnist 데이터셋 모듈을 사용합니다.
fashion_mnist 모듈은 데이터셋을 반환하는 load_data() 함수를 포함하는데, load_data() 함수를 호출하면 NumPy 어레이의 튜플을 반환합니다.
train_images와 train_labels는 Neural Network 모델의 훈련 (training)에 사용되고,
test_images와 test_labels는 테스트 (test)에 사용됩니다.
Fashion MNIST 데이터셋 살펴보기¶
train_images와 train_labels의 첫번째 요소를 각각 출력해 보겠습니다.
print(train_images[0])
print(train_labels[0])
[[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 13 73 0 0 1 4 0 0 0 0 1 1 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 3 0 36 136 127 62 54 0 0 0 1 3 4 0 0 3]
[ 0 0 0 0 0 0 0 0 0 0 0 0 6 0 102 204 176 134 144 123 23 0 0 0 0 12 10 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 155 236 207 178 107 156 161 109 64 23 77 130 72 15]
[ 0 0 0 0 0 0 0 0 0 0 0 1 0 69 207 223 218 216 216 163 127 121 122 146 141 88 172 66]
[ 0 0 0 0 0 0 0 0 0 1 1 1 0 200 232 232 233 229 223 223 215 213 164 127 123 196 229 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 183 225 216 223 228 235 227 224 222 224 221 223 245 173 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 193 228 218 213 198 180 212 210 211 213 223 220 243 202 0]
[ 0 0 0 0 0 0 0 0 0 1 3 0 12 219 220 212 218 192 169 227 208 218 224 212 226 197 209 52]
[ 0 0 0 0 0 0 0 0 0 0 6 0 99 244 222 220 218 203 198 221 215 213 222 220 245 119 167 56]
[ 0 0 0 0 0 0 0 0 0 4 0 0 55 236 228 230 228 240 232 213 218 223 234 217 217 209 92 0]
[ 0 0 1 4 6 7 2 0 0 0 0 0 237 226 217 223 222 219 222 221 216 223 229 215 218 255 77 0]
[ 0 3 0 0 0 0 0 0 0 62 145 204 228 207 213 221 218 208 211 218 224 223 219 215 224 244 159 0]
[ 0 0 0 0 18 44 82 107 189 228 220 222 217 226 200 205 211 230 224 234 176 188 250 248 233 238 215 0]
[ 0 57 187 208 224 221 224 208 204 214 208 209 200 159 245 193 206 223 255 255 221 234 221 211 220 232 246 0]
[ 3 202 228 224 221 211 211 214 205 205 205 220 240 80 150 255 229 221 188 154 191 210 204 209 222 228 225 0]
[ 98 233 198 210 222 229 229 234 249 220 194 215 217 241 65 73 106 117 168 219 221 215 217 223 223 224 229 29]
[ 75 204 212 204 193 205 211 225 216 185 197 206 198 213 240 195 227 245 239 223 218 212 209 222 220 221 230 67]
[ 48 203 183 194 213 197 185 190 194 192 202 214 219 221 220 236 225 216 199 206 186 181 177 172 181 205 206 115]
[ 0 122 219 193 179 171 183 196 204 210 213 207 211 210 200 196 194 191 195 191 198 192 176 156 167 177 210 92]
[ 0 0 74 189 212 191 175 172 175 181 185 188 189 188 193 198 204 209 210 210 211 188 188 194 192 216 170 0]
[ 2 0 0 0 66 200 222 237 239 242 246 243 244 221 220 193 191 179 182 182 181 176 166 168 99 58 0 0]
[ 0 0 0 0 0 0 0 40 61 44 72 41 35 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]]
9
train_images는 0에서 255 사이의 값을 갖는 28x28 크기의 NumPy 어레이를 갖는 어레이이고,
train_labels는 0에서 9까지의 정수 값을 갖는 어레이입니다.
0에서 9까지의 정수 값은 이미지(옷)의 클래스를 나타내는 레이블입니다. 각각의 레이블과 클래스는 아래와 같습니다.
첫번째 train_images를 Matplotlib을 이용해서 이미지로 나타내보면,
아래와 같은 이미지가 출력됩니다.
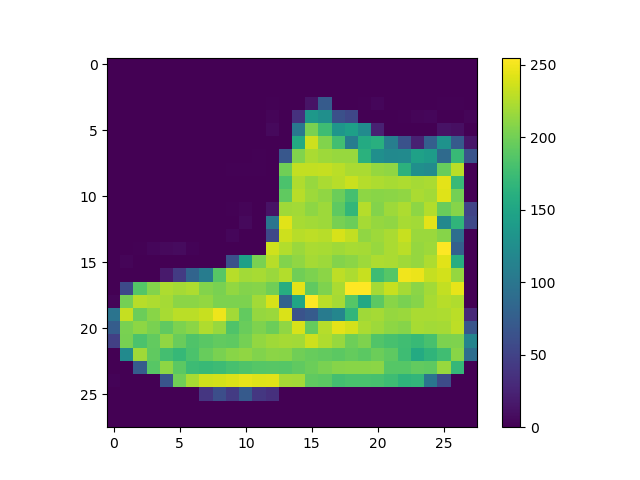
traing_images 샘플 출력하기.¶
print(train_images.shape)
print(train_labels.shape)
print(test_images.shape)
print(test_labels.shape)
(60000, 28, 28)
(60000,)
(10000, 28, 28)
(10000,)
각 어레이의 형태 (shape)를 출력해보면,
train_images와 test_images는 각각 (28x28)의 형태를 갖는 60000개, 10000개 이미지의 어레이,
train_labels와 test_labels는 각각 0에서 9 사이의 정수 60000개, 10000개의 어레이임을 알 수 있습니다.
Fashion MNIST 데이터셋 전처리하기¶
# 2. 데이터 전처리
train_images, test_images = train_images / 255.0, test_images / 255.0
0에서 255 사이의 값을 갖는 훈련/테스트 데이터들을 0.0~1.0 사이의 값을 갖도록 변환합니다.
모델 구성하기¶
# 3. 모델 구성
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(512, activation='relu'),
tf.keras.layers.Dense(10, activation='softmax')
])
MNIST 인식 예제와 같이 Sequential() 클래스를 이용해서 신경망 모델을 순서대로 구성합니다.
tf.keras.layers.Flatten 클래스는 아래 그림과 같이 입력 데이터를 1차원으로 변환합니다.
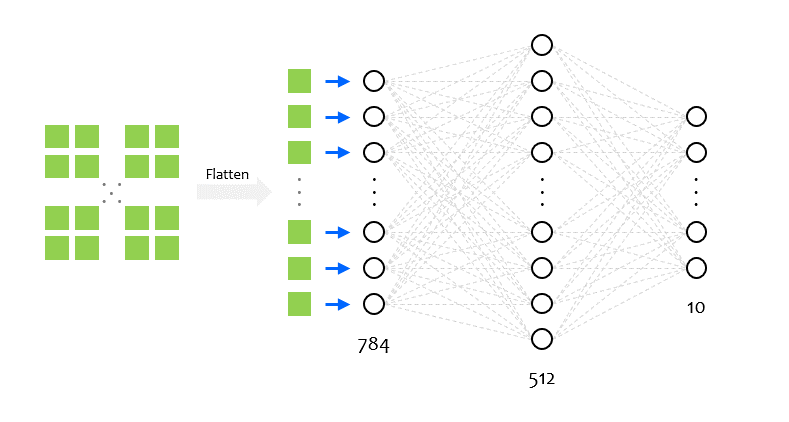
모델 컴파일하기¶
compile() 메서드를 이용해서 모델을 훈련하는데 사용할 옵티마이저, 손실 함수, 지표를 설정합니다.
# 4. 모델 컴파일
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
손실 함수 (loss function)는 훈련 과정에서 모델의 오차를 측정하는데 사용됩니다.
옵티마이저 (optimizer)는 데이터와 손실 함수를 바탕으로 모델 (의 웨이트와 바이어스)을 업데이트하는 방식을 말합니다.
지표 (metrics)는 훈련과 테스트 단계를 평가하기 위해 사용됩니다.
‘accuracy’로 설정하면, 이미지를 올바르게 분류한 비율로 모델을 평가합니다.
모델 훈련하기¶
# 5. 모델 훈련
model.fit(train_images, train_labels, epochs=5)
fit() 메서드에 훈련에 사용할 이미지 데이터와 레이블을 입력해줍니다.
에포크 (epochs)는 60000개의 전체 이미지를 몇 번 학습할지 설정합니다.
아래와 같은 훈련 과정이 출력됩니다.
Epoch 1/5
32/60000 [..............................] - ETA: 6:13 - loss: 2.4037 - accuracy: 0.0625
352/60000 [..............................] - ETA: 42s - loss: 1.4676 - accuracy: 0.4830
640/60000 [..............................] - ETA: 28s - loss: 1.2536 - accuracy: 0.5375
1024/60000 [..............................] - ETA: 20s - loss: 1.0536 - accuracy: 0.6172
1440/60000 [..............................] - ETA: 16s - loss: 0.9693 - accuracy: 0.6465
1888/60000 [..............................] - ETA: 14s - loss: 0.9230 - accuracy: 0.6600
2272/60000 [>.............................] - ETA: 13s - loss: 0.8733 - accuracy: 0.6787
2720/60000 [>.............................] - ETA: 11s - loss: 0.8461 - accuracy: 0.6893
3168/60000 [>.............................] - ETA: 11s - loss: 0.8126 - accuracy: 0.7027
3584/60000 [>.............................] - ETA: 10s - loss: 0.7877 - accuracy: 0.7115
3936/60000 [>.............................] - ETA: 10s - loss: 0.7695 - accuracy: 0.7200
4320/60000 [=>............................] - ETA: 9s - loss: 0.7593 - accuracy: 0.7257
4736/60000 [=>............................] - ETA: 9s - loss: 0.7494 - accuracy: 0.7314
5056/60000 [=>............................] - ETA: 9s - loss: 0.7350 - accuracy: 0.7366
5376/60000 [=>............................] - ETA: 9s - loss: 0.7242 - accuracy: 0.7398
5760/60000 [=>............................] - ETA: 9s - loss: 0.7114 - accuracy: 0.7446
6176/60000 [==>...........................] - ETA: 9s - loss: 0.7018 - accuracy: 0.7494
6592/60000 [==>...........................] - ETA: 8s - loss: 0.6903 - accuracy: 0.7544
6976/60000 [==>...........................] - ETA: 8s - loss: 0.6847 - accuracy: 0.7556
7296/60000 [==>...........................] - ETA: 8s - loss: 0.6785 - accuracy: 0.7571
7712/60000 [==>...........................] - ETA: 8s - loss: 0.6773 - accuracy: 0.7584
8160/60000 [===>..........................] - ETA: 8s - loss: 0.6706 - accuracy: 0.7614
8672/60000 [===>..........................] - ETA: 8s - loss: 0.6641 - accuracy: 0.7641
9184/60000 [===>..........................] - ETA: 7s - loss: 0.6584 - accuracy: 0.7658
9696/60000 [===>..........................] - ETA: 7s - loss: 0.6510 - accuracy: 0.7683
10176/60000 [====>.........................] - ETA: 7s - loss: 0.6465 - accuracy: 0.7710
10592/60000 [====>.........................] - ETA: 7s - loss: 0.6400 - accuracy: 0.7723
11040/60000 [====>.........................] - ETA: 7s - loss: 0.6378 - accuracy: 0.7739
모델의 정확도 평가하기¶
evaluate() 메서드를 이용해서 손실 (loss)과 정확도 (accuracy)를 각각 얻을 수 있습니다.
# 6. 정확도 평가하기
loss, accuracy = model.evaluate(test_images, test_labels)
print(loss, accuracy)
0.35106261382102966 0.8713
5회 epoch의 학습을 통해 10000개의 테스트 이미지를 87%의 정확도로 분류할 수 있음을 의미합니다.
예측하기¶
predict() 메서드를 사용하면 모델이 각 이미지의 클래스를 예측하는 결과를 확인할 수 있습니다.
# 7. 예측하기
predictions = model.predict(test_images)
print(predictions[0])
print(np.argmax(predictions[0]))
[3.3880130e-07 1.6222993e-08 1.0470003e-07 1.2482052e-07 2.4020338e-08 1.4695596e-04 9.3243568e-07 1.7916959e-02 1.7079768e-06 9.8193282e-01]
9
predictions는 각 test_images에 대한 신경망의 출력값을 나타내는 어레이입니다.
첫번째 예측 predictions[0]을 출력해보면 10개의 값을 갖는 어레이이며, 입력 이미지 데이터가 열 개의 숫자 중 어떤 숫자일 확률을 의미합니다.
np.argmax() 함수를 이용해서 가장 높은 값을 갖는 인덱스를 확인해보면 9를 출력합니다.
즉, 학습된 신경망은 이 이미지가 ankle boot라고 예측합니다.
뉴런의 개수의 영향¶
가운데 뉴런층의 뉴런 노드의 개수를 조절하면 훈련에 어떤 영향을 미치는지 알아봅니다.
아래 그림과 같이 뉴런 노드의 개수를 128, 512, 1024로 변화시키면서 세 가지 경우에 대해
훈련 과정의 손실과 정확도를 확인해보겠습니다.
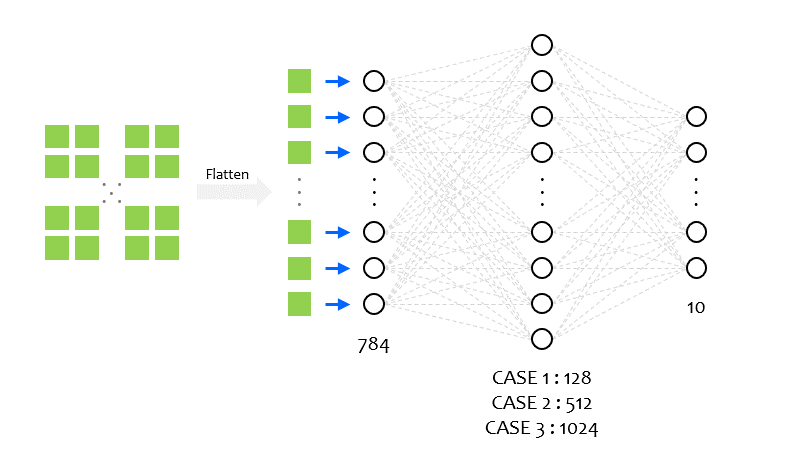
# 3. 모델 구성
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(128, activation='relu'), ## CASE 1
# tf.keras.layers.Dense(512, activation='relu'), ## CASE 2
# tf.keras.layers.Dense(1024, activation='relu'), ## CASE 3
tf.keras.layers.Dense(10, activation='softmax')
])
## CASE 1
Epoch 1/5
1875/1875 [==============================] - 3s 2ms/step - loss: 0.4990 - accuracy: 0.8238
Epoch 2/5
1875/1875 [==============================] - 3s 2ms/step - loss: 0.3752 - accuracy: 0.8650
Epoch 3/5
1875/1875 [==============================] - 3s 2ms/step - loss: 0.3379 - accuracy: 0.8763
Epoch 4/5
1875/1875 [==============================] - 3s 2ms/step - loss: 0.3107 - accuracy: 0.8853
Epoch 5/5
1875/1875 [==============================] - 4s 2ms/step - loss: 0.2938 - accuracy: 0.8930
313/313 [==============================] - 0s 1ms/step - loss: 0.3664 - accuracy: 0.8695
0.3664253056049347 0.8694999814033508
## CASE 2
Epoch 1/5
1875/1875 [==============================] - 7s 4ms/step - loss: 0.4760 - accuracy: 0.8302
Epoch 2/5
1875/1875 [==============================] - 7s 4ms/step - loss: 0.3585 - accuracy: 0.8672
Epoch 3/5
1875/1875 [==============================] - 7s 4ms/step - loss: 0.3239 - accuracy: 0.8812
Epoch 4/5
1875/1875 [==============================] - 7s 4ms/step - loss: 0.2972 - accuracy: 0.8896
Epoch 5/5
1875/1875 [==============================] - 7s 4ms/step - loss: 0.2797 - accuracy: 0.8965
313/313 [==============================] - 1s 2ms/step - loss: 0.3516 - accuracy: 0.8775
0.3515831232070923 0.8774999976158142
## CASE 3
Epoch 1/5
1875/1875 [==============================] - 12s 6ms/step - loss: 0.4747 - accuracy: 0.8292
Epoch 2/5
1875/1875 [==============================] - 12s 7ms/step - loss: 0.3587 - accuracy: 0.8689
Epoch 3/5
1875/1875 [==============================] - 12s 7ms/step - loss: 0.3187 - accuracy: 0.8818
Epoch 4/5
1875/1875 [==============================] - 13s 7ms/step - loss: 0.2984 - accuracy: 0.8892
Epoch 5/5
1875/1875 [==============================] - 12s 7ms/step - loss: 0.2797 - accuracy: 0.8959
313/313 [==============================] - 1s 3ms/step - loss: 0.3369 - accuracy: 0.8822
0.3369075059890747 0.8822000026702881
에포크에 따른 손실과 정확도를 그래프로 표현하면 아래와 같습니다.
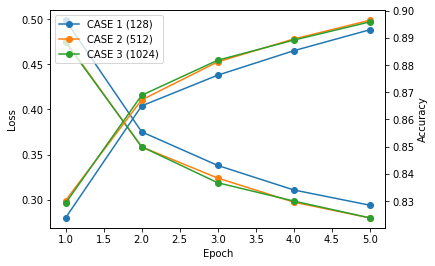
뉴런 노드의 개수가 증가하면 훈련 과정에서 손실 값이 감소하고 테스트 정확도는 증가하는 경향이 있습니다.
하지만 계산과 최적화를 필요로 하는 파라미터의 숫자가 증가하기 때문에 훈련에 걸리는 시간은 증가합니다.
512개와 1024개에서 손실과 정확도의 증가가 크지 않은 이유는 Fashion MNIST 분류 문제가 비교적 간단한 문제이기 때문입니다.
따라서 문제에 맞게 적절한 개수의 뉴런을 사용하면서 짧은 훈련 시간 동안 높은 정확도를 얻는 것이 좋습니다.
콜백 (Callback) 사용하기¶
tf.keras.callbacks 모듈의 Callback 클래스를 사용하면,
훈련 중에 손실 값이 특정 기준 미만이 되었을 때 훈련을 중단할 수 있습니다.
import tensorflow as tf
class myCallback(tf.keras.callbacks.Callback):
def on_epoch_end(self, epoch, logs={}):
if logs.get('loss') < 0.3:
print('\n훈련을 중지합니다.')
self.model.stop_training = True
callbacks = myCallback()
# 1. Fashion MNIST 데이터셋 임포트
fashion_mnist = tf.keras.datasets.fashion_mnist
(train_images, train_labels), (test_images, test_labels) = fashion_mnist.load_data()
# 2. 데이터 전처리
train_images, test_images = train_images / 255.0, test_images / 255.0
# 3. 모델 구성
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(512, activation='relu'),
tf.keras.layers.Dense(10, activation='softmax')
])
# 4. 모델 컴파일
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# 5. 모델 훈련
model.fit(train_images, train_labels, epochs=5, callbacks=[callbacks])
Epoch 1/5
1875/1875 [==============================] - 7s 4ms/step - loss: 0.4721 - accuracy: 0.8308
Epoch 2/5
1875/1875 [==============================] - 7s 4ms/step - loss: 0.3585 - accuracy: 0.8671
Epoch 3/5
1875/1875 [==============================] - 7s 3ms/step - loss: 0.3221 - accuracy: 0.8815
Epoch 4/5
1861/1875 [============================>.] - ETA: 0s - loss: 0.2990 - accuracy: 0.8909
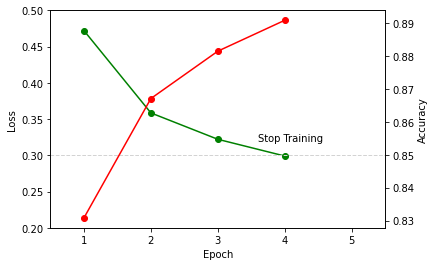
훈련을 중지합니다.
1875/1875 [==============================] - 7s 4ms/step - loss: 0.2989 - accuracy: 0.8909
<tensorflow.python.keras.callbacks.History at 0x7fdbd2df17f0>
우선 myCallback 클래스에 조건식을 사용해서 훈련을 중단할 조건을 지정하고,
fit() 메서드에 callbacks 파라미터를 사용해서 이 클래스가 호출되도록 합니다.
on_epoch_end는 각 에포크 (epoch)의 끝에 호출되는 메서드입니다.
한 에포크가 끝나고 손실 값 (loss)이 0.3 미만이라면 훈련을 중단하도록 해주었습니다.
예제에서 총 5회 에포크의 훈련을 설정했음에도 4회 에포크에서 훈련이 중단되었습니다.
에포크 (epoch)에 따른 손실 값과 정확도는 아래와 같습니다.
Fashion MNIST 이미지 인식 예제¶
전체 코드는 아래와 같습니다.
import tensorflow as tf
import numpy as np
# 1. Fashion MNIST 데이터셋 임포트
fashion_mnist = tf.keras.datasets.fashion_mnist
(train_images, train_labels), (test_images, test_labels) = fashion_mnist.load_data()
# 2. 데이터 전처리
train_images, test_images = train_images / 255.0, test_images / 255.0
# 3. 모델 구성
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(512, activation='relu'),
tf.keras.layers.Dense(10, activation='softmax')
])
# 4. 모델 컴파일
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# 5. 모델 훈련
model.fit(train_images, train_labels, epochs=5)
# 6. 정확도 평가하기
loss, accuracy = model.evaluate(test_images, test_labels)
print(loss, accuracy)
# 7. 예측하기
predictions = model.predict(test_images)
print(predictions[0])
print(np.argmax(predictions[0]))