Contents
- TensorFlow - 구글 머신러닝 플랫폼
- 1. 텐서 기초 살펴보기
- 2. 간단한 신경망 만들기
- 3. 손실 함수 살펴보기
- 4. 옵티마이저 사용하기
- 5. AND 로직 연산 학습하기
- 6. 뉴런층의 속성 확인하기
- 7. 뉴런층의 출력 확인하기
- 8. MNIST 손글씨 이미지 분류하기
- 9. Fashion MNIST 이미지 분류하기
- 10. 합성곱 신경망 사용하기
- 11. 말과 사람 이미지 분류하기
- 12. 고양이와 개 이미지 분류하기
- 13. 이미지 어그멘테이션의 효과
- 14. 전이 학습 활용하기
- 15. 다중 클래스 분류 문제
- 16. 시냅스 가중치 얻기
- 17. 시냅스 가중치 적용하기
- 18. 모델 시각화하기
- 19. 훈련 과정 시각화하기
- 20. 모델 저장하고 복원하기
- 21. 시계열 데이터 예측하기
- 22. 자연어 처리하기 1
- 23. 자연어 처리하기 2
- 24. 자연어 처리하기 3
- 25. Reference
- tf.cast
- tf.constant
- tf.keras.activations.exponential
- tf.keras.activations.linear
- tf.keras.activations.relu
- tf.keras.activations.sigmoid
- tf.keras.activations.softmax
- tf.keras.activations.tanh
- tf.keras.datasets
- tf.keras.layers.Conv2D
- tf.keras.layers.Dense
- tf.keras.layers.Flatten
- tf.keras.layers.GlobalAveragePooling2D
- tf.keras.layers.InputLayer
- tf.keras.layers.ZeroPadding2D
- tf.keras.metrics.Accuracy
- tf.keras.metrics.BinaryAccuracy
- tf.keras.Sequential
- tf.linspace
- tf.ones
- tf.random.normal
- tf.range
- tf.rank
- tf.TensorShape
- tf.zeros
Tutorials
- Python Tutorial
- NumPy Tutorial
- Matplotlib Tutorial
- PyQt5 Tutorial
- BeautifulSoup Tutorial
- xlrd/xlwt Tutorial
- Pillow Tutorial
- Googletrans Tutorial
- PyWin32 Tutorial
- PyAutoGUI Tutorial
- Pyperclip Tutorial
- TensorFlow Tutorial
- Tips and Examples
10. 합성곱 신경망 사용하기¶
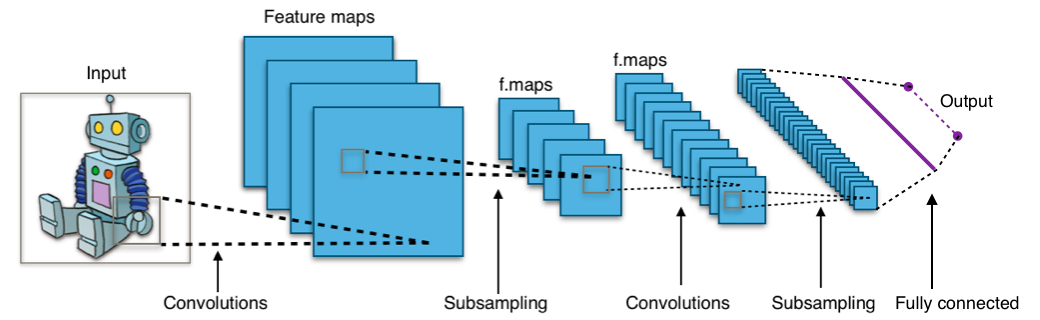
합성곱 신경망 (Convolutional neural network, CNN)은 시각적 이미지 분석 및 분류에 가장 일반적으로 사용되는 인공신경망입니다.
이번 페이지에서는 합성곱 신경망을 사용해서 MNIST 이미지 데이터셋을 분류해보겠습니다.
순서는 아래와 같습니다.
1. MNIST 데이터셋 불러오기¶
import tensorflow as tf
from tensorflow.keras import datasets, layers, models
# 1. MNIST 데이터셋 불러오기
(train_images, train_labels), (test_images, test_labels) = datasets.mnist.load_data()
앞의 예제에서와 같이 load_data()를 이용해서 keras.datasets에서 mnist 데이터셋을 불러옵니다.

2. 데이터 전처리하기¶
# 2. 데이터 전처리하기
train_images = train_images.reshape((60000, 28, 28, 1))
test_images = test_images.reshape((10000, 28, 28, 1))
train_images, test_images = train_images / 255.0, test_images / 255.0
mnist 데이터셋의 자료형을 출력해보면 numpy.ndarray 클래스임을 알 수 있습니다.
NumPy의 reshape() 함수를 이용해서 적절한 형태로 변환하고,
0~255 사이의 값을 갖는 데이터를 0.0~1.0 사이의 값을 갖도록, 255.0으로 나눠줍니다.
3. 합성곱 신경망 구성하기¶
# 3. 합성곱 신경망 구성하기
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.summary()
tf.keras.models 모듈의 Sequential 클래스를 사용해서 인공신경망의 각 층을 순서대로 쌓을 수 있습니다.
add() 메서드를 이용해서 합성곱 층 Conv2D와 Max pooling 층 MaxPooling2D를 반복해서 구성합니다.
첫번째 Conv2D 층의 첫번째 인자 32는 filters 값입니다.
합성곱 연산에서 사용되는 필터 (filter)는 이미지에서 특징 (feature)을 분리해내는 기능을 합니다.
filters의 값은 합성곱에 사용되는 필터의 종류 (개수)이며, 출력 공간의 차원 (깊이)을 결정합니다.
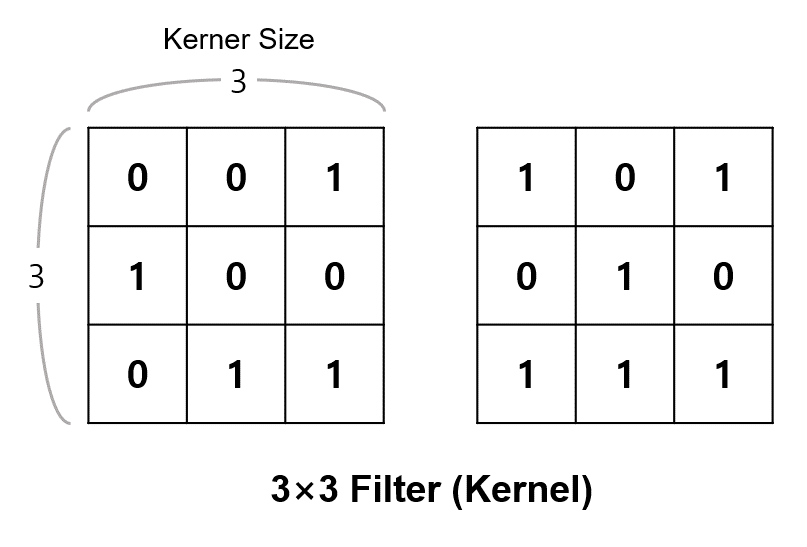
두번째 인자 (3, 3)은 kernel_size 값입니다.
kernel_size는 합성곱에 사용되는 필터 (=커널)의 크기입니다.
아래와 같은 3×3 크기의 필터가 사용되며, 합성곱 연산이 이루어지고 나면 이미지는 (28, 28) 크기에서 (26, 26)이 됩니다.
활성화함수 (Activation function)는 ‘relu’로 지정하고,
입력 데이터의 형태 (input_shape)는 아래와 같이 MNIST 숫자 이미지 하나의 형태에 해당하는 (28, 28, 1)로 설정합니다.
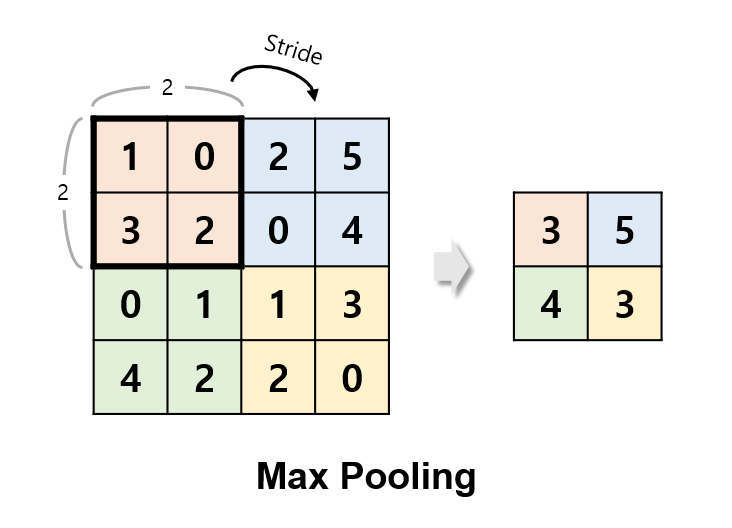
풀링 (Pooling)은 합성곱에 의해 얻어진 Feature map으로부터 값을 샘플링해서 정보를 압축하는 과정을 의미합니다.
맥스풀링 (Max-pooling)은 특정 영역에서 가장 큰 값을 샘플링하는 풀링 방식이며,
예제에서는 풀링 필터의 크기를 2×2 영역으로 설정했습니다.
strides는 풀링 필터를 이동시키는 간격을 의미합니다.
strides를 지정해주지 않으면 (None), 풀링 필터의 크기와 같아서 영역의 오버랩 없이 풀링이 이루어집니다.
따라서 풀링이 이루어지고 나면, (26, 26) 크기의 이미지는 (13, 13) 크기가 됩니다.
summary() 메서드를 이용해서 지금까지 구성한 신경망에 대한 정보를 출력할 수 있습니다.
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 26, 26, 32) 320
_________________________________________________________________
max_pooling2d (MaxPooling2 (None, 13, 13, 32) 0
_________________________________________________________________
conv2d_1 (Conv2D) (None, 11, 11, 64) 18496
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 5, 5, 64) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 3, 3, 64) 36928
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 (None, 1, 1, 64) 0
=================================================================
Total params: 55,744
Trainable params: 55,744
Non-trainable params: 0
_________________________________________________________________
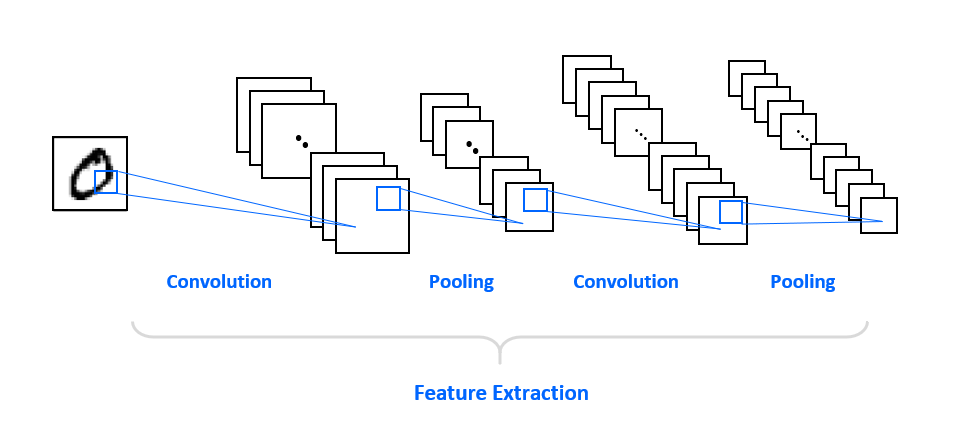
지금까지 구성한 신경망의 구조를 그림으로 나타내면 아래와 같습니다.
이러한 합성곱, 풀링 층은 특성 추출 (Feature Extraction)을 담당하며, 전체 합성곱 신경망의 앞부분을 구성합니다.
4. Dense 층 추가하기¶
# 4. Dense 층 추가하기
model.add(layers.Flatten())
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(10, activation='softmax'))
model.summary()
합성곱 층에 이어 뒷부분에는 분류를 담당하는 Dense 층 (Fully-connected layer)을 세 개 추가합니다.
마지막 출력층 노드의 개수는 열 개로 하고 ‘softmax’ 활성화함수를 사용합니다.
summary() 메서드를 이용해서 지금까지 구성한 신경망에 대한 정보를 다시 출력해 보겠습니다.
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 26, 26, 32) 320
_________________________________________________________________
max_pooling2d (MaxPooling (None, 13, 13, 32) 0
_________________________________________________________________
conv2d_1 (Conv2D) (None, 11, 11, 64) 18496
_________________________________________________________________
max_pooling2d_1 (MaxPooling (None, 5, 5, 64) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 3, 3, 64) 36928
_________________________________________________________________
max_pooling2d_2 (MaxPooling (None, 1, 1, 64) 0
_________________________________________________________________
flatten (Flatten) (None, 64) 0
_________________________________________________________________
dense (Dense) (None, 64) 4160
_________________________________________________________________
dense_1 (Dense) (None, 10) 650
=================================================================
Total params: 60,554
Trainable params: 60,554
Non-trainable params: 0
_________________________________________________________________
flatten, dense, dense_1 이라는 세 개의 층이 추가되고,
훈련 가능한 파라미터의 수가 55,744개에서 60,554개로 증가했습니다.
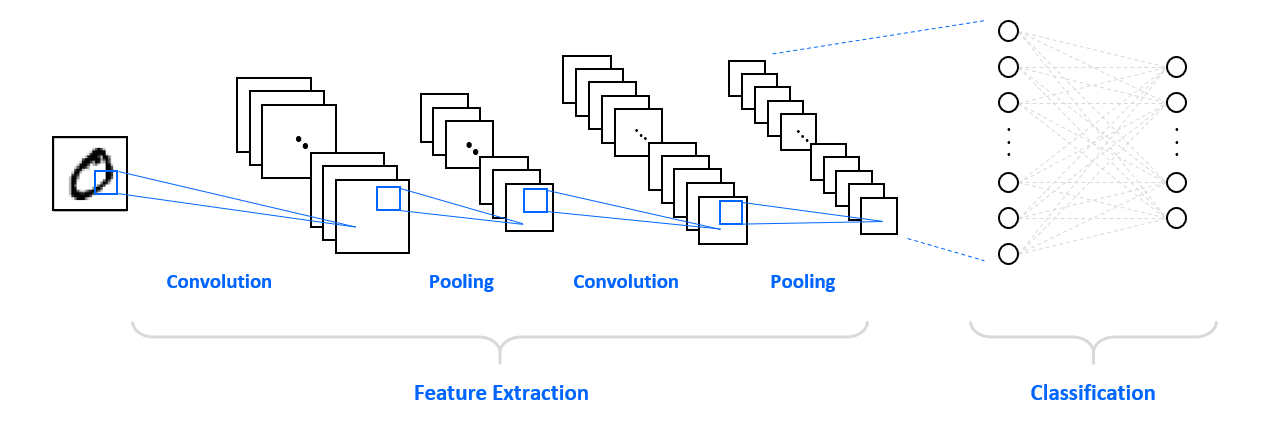
지금까지 구성한 전체 신경망의 구조를 그림으로 나타내면 아래와 같습니다.
여러 층의 합성곱, 풀링층과 Dense 층이 반복적으로 구성되었습니다.
아래의 코드는 앞에서 설명한 합성곱 신경망과 Dense 층을 구성하는 또 다른 방식을 보여줍니다.
model = tf.keras.models.Sequential([
tf.keras.layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)),
tf.keras.layers.MaxPooling2D(2, 2),
tf.keras.layers.Conv2D(64, (3, 3), activation='relu'),
tf.keras.layers.MaxPooling2D(2, 2),
tf.keras.layers.Conv2D(64, (3, 3), activation='relu'),
tf.keras.layers.MaxPooling2D(2, 2),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dense(10, activation='softmax')
])
model.summary()
5. 모델 컴파일하기¶
# 5. 모델 컴파일하기
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
앞의 예제와 마찬가지로 compile() 메서드를 이용해서 옵티마이저, 손실 함수, 지표를 각각 설정해줍니다.
6. 훈련하기¶
# 6. 훈련하기
model.fit(train_images, train_labels, epochs=5)
fit() 메서드에 미리 준비한 train_images와 train_labels, 5회의 epochs를 입력하고 훈련을 진행합니다.
아래와 같이 훈련의 진행 상황이 출력됩니다.
Epoch 1/5
32/60000 [..............................] - ETA: 9:37 - loss: 2.2930 - accuracy: 0.1875
128/60000 [..............................] - ETA: 2:51 - loss: 2.2807 - accuracy: 0.1328
224/60000 [..............................] - ETA: 1:54 - loss: 2.2566 - accuracy: 0.1964
320/60000 [..............................] - ETA: 1:30 - loss: 2.2268 - accuracy: 0.2688
384/60000 [..............................] - ETA: 1:24 - loss: 2.2049 - accuracy: 0.3021
480/60000 [..............................] - ETA: 1:13 - loss: 2.1633 - accuracy: 0.3083
576/60000 [..............................] - ETA: 1:06 - loss: 2.1073 - accuracy: 0.3281
672/60000 [..............................] - ETA: 1:01 - loss: 2.0411 - accuracy: 0.3571
768/60000 [..............................] - ETA: 1:00 - loss: 1.9643 - accuracy: 0.3906
864/60000 [..............................] - ETA: 58s - loss: 1.8911 - accuracy: 0.4201
960/60000 [..............................] - ETA: 56s - loss: 1.8120 - accuracy: 0.4469
1056/60000 [..............................] - ETA: 54s - loss: 1.7266 - accuracy: 0.4716
1120/60000 [..............................] - ETA: 53s - loss: 1.6847 - accuracy: 0.4875
1216/60000 [..............................] - ETA: 52s - loss: 1.6315 - accuracy: 0.5000
1280/60000 [..............................] - ETA: 52s - loss: 1.5871 - accuracy: 0.5109
1376/60000 [..............................] - ETA: 51s - loss: 1.5230 - accuracy: 0.5305
1440/60000 [..............................] - ETA: 51s - loss: 1.4813 - accuracy: 0.5424
1536/60000 [..............................] - ETA: 50s - loss: 1.4202 - accuracy: 0.5632
1664/60000 [..............................] - ETA: 49s - loss: 1.3670 - accuracy: 0.5829
1760/60000 [..............................] - ETA: 48s - loss: 1.3205 - accuracy: 0.5966
7. 모델 평가하기¶
# 7. 모델 평가하기
loss, acc = model.evaluate(test_images, test_labels, verbose=2)
10000/10000 - 2s - loss: 0.0248 - accuracy: 0.9923
evaluate() 메서드에 test_images와 test_labels를 입력함으로써 모델을 평가할 수 있습니다.
손실 함수 값이 0.0248, 그리고 정확도가 0.9923입니다.
합성곱 신경망을 사용해서 이미지 분류를 수행할 때, 단순한 Dense 층으로만 이루어진 신경망으로 학습한 경우의 정확도인 0.9802에 비해
더 높은 정확도를 얻을 수 있음을 알 수 있습니다. (MNIST 손글씨 인식 참고)
전체 코드는 아래와 같습니다.
CNN을 이용한 MNIST 이미지 인식 예제¶
import tensorflow as tf
from tensorflow.keras import datasets, layers, models
# 1. MNIST 데이터셋 불러오기
(train_images, train_labels), (test_images, test_labels) = datasets.mnist.load_data()
# 2. 데이터 전처리하기
train_images = train_images.reshape((60000, 28, 28, 1))
test_images = test_images.reshape((10000, 28, 28, 1))
train_images, test_images = train_images / 255.0, test_images / 255.0
# 3. 합성곱 신경망 구성하기
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.summary()
# 4. Dense 층 추가하기
model.add(layers.Flatten())
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(10, activation='softmax'))
model.summary()
# 5. 모델 컴파일하기
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# 6. 훈련하기
model.fit(train_images, train_labels, epochs=5)
# 7. 모델 평가하기
loss, acc = model.evaluate(test_images, test_labels, verbose=2)