QTextBrowser (Advanced)¶
Now let’s use web crawling to seek out BBC News search results headlines.
Example¶
import sys
from PyQt5.QtWidgets import QApplication, QWidget, QLineEdit, QPushButton, QLabel, QTextBrowser, QGridLayout
import requests
from bs4 import BeautifulSoup
class MyApp(QWidget):
def __init__(self):
super().__init__()
self.initUI()
def initUI(self):
self.le = QLineEdit()
self.le.setPlaceholderText('Enter your search word')
self.le.returnPressed.connect(self.crawl_news)
self.btn = QPushButton('Search')
self.btn.clicked.connect(self.crawl_news)
self.lbl = QLabel('')
self.tb = QTextBrowser()
self.tb.setAcceptRichText(True)
self.tb.setOpenExternalLinks(True)
grid = QGridLayout()
grid.addWidget(self.le, 0, 0, 1, 3)
grid.addWidget(self.btn, 0, 3, 1, 1)
grid.addWidget(self.lbl, 1, 0, 1, 4)
grid.addWidget(self.tb, 2, 0, 1, 4)
self.setLayout(grid)
self.setWindowTitle('Web Crawler')
self.setGeometry(100, 100, 700, 450)
self.show()
def crawl_news(self):
search_word = self.le.text()
if search_word:
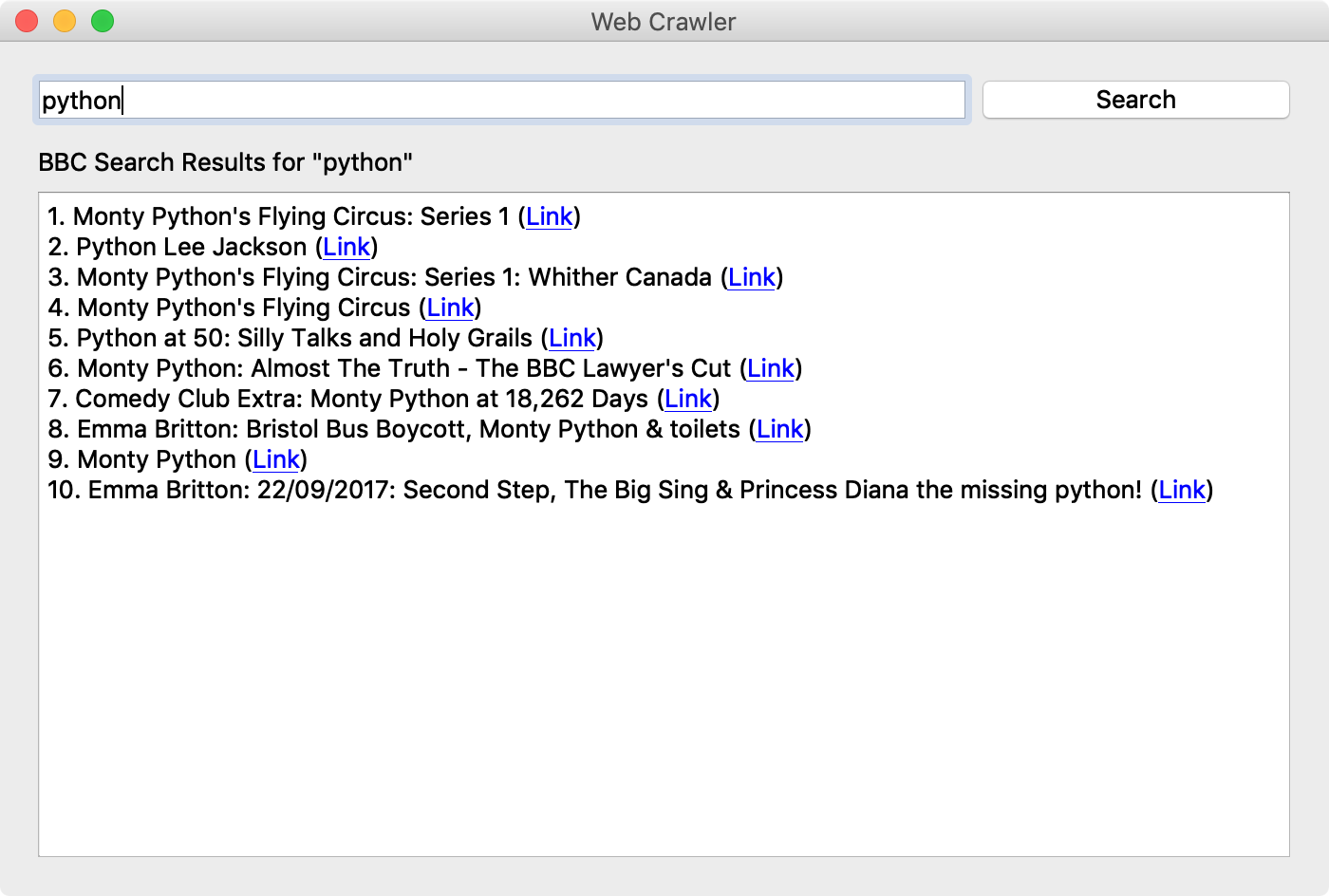
self.lbl.setText('BBC Search Results for "' + search_word + '"')
self.tb.clear()
url_search = 'https://www.bbc.co.uk/search?q='
url = url_search + search_word
r = requests.get(url)
html = r.content
soup = BeautifulSoup(html, 'html.parser')
titles_html = soup.select('.search-results > li > article > div > h1 > a')
for i in range(len(titles_html)):
title = titles_html[i].text
link = titles_html[i].get('href')
self.tb.append(str(i+1) + '. ' + title + ' (' + '<a href="' + link + '">Link</a>' + ')')
if __name__ == '__main__':
app = QApplication(sys.argv)
ex = MyApp()
sys.exit(app.exec_())
Enter a search term and click the button to output the BBC News search results and links to a text browser.
Description¶
import sys
from PyQt5.QtWidgets import QApplication, QWidget, QLineEdit, QPushButton, QLabel, QTextBrowser, QGridLayout
import requests
from bs4 import BeautifulSoup
In addition to the modules related to PyQt5, open the requests, BeautifulSoup libraries required for crawling.
self.le = QLineEdit()
self.le.setPlaceholderText('Enter your search word')
self.le.returnPressed.connect(self.crawl_news)
Use QLineEdit() to create a line editor for entering dates.
Use setPlaceholderText to make the line editor have ‘Enter your search word’ displayed.
returnPressed is the signal that’s generated when the Enter key is pressed. Connect to the crawl_news method.
self.btn = QPushButton('Search')
self.btn.clicked.connect(self.crawl_news)
Create the ‘Search’ button. Clicking the button also invokes the crawl_news method.
self.tb = QTextBrowser()
self.tb.setAcceptRichText(True)
self.tb.setOpenExternalLinks(True)
Create a text browser using QTextBrowser() class.
The setAcceptRichText, which allows formatted text, is set to True by default so you don’t have to create it.
Allow external links using setOpenExternalLinks().
grid = QGridLayout()
grid.addWidget(self.le, 0, 0, 1, 3)
grid.addWidget(self.btn, 0, 3, 1, 1)
grid.addWidget(self.lbl, 1, 0, 1, 4)
grid.addWidget(self.tb, 2, 0, 1, 4)
self.setLayout(grid)
Using the grid layout, place the line editor(self.le), ‘Search’ button(self.btn), label(self), and text browser (self.tb) in the appropriate location.
The first parameter in addWidget stands for the widget you want to add, the second and third for the location of the row and column, and the third and fourth for the space in which the row and column occupy.
def crawl_news(self):
search_word = self.le.text()
if search_word:
self.lbl.setText('BBC Search Results for "' + search_word + '"')
self.tb.clear()
Assign the text entered in the line editor to search_word. If there is a search term entered, make ‘BBC Search Results for “search_word“‘ show on the label.
Use self.tb.clear() to remove the text previously displayed in the text browser.
url_search = 'https://www.bbc.co.uk/search?q='
url = url_search + search_word
r = requests.get(url)
html = r.content
soup = BeautifulSoup(html, 'html.parser')
titles_html = soup.select('.search-results > li > article > div > h1 > a')
Go to that address and select the text that corresponds to the title of your news search results.
for i in range(len(titles_html)):
title = titles_html[i].text
link = titles_html[i].get('href')
self.tb.append(str(i+1) + '. ' + title + ' (' + '<a href="' + link + '">Link</a>' + ')')
titles_html[i].text is the text within a tag, and titles_html[i].get(‘href’) is the link address for a tag.
Add a title and link to the news in the text browser.